Introduction
Nous aborderons la génération de code selon une approche fonctionelle. En effet, le générateur de code ayant besoin de la structure aborescente du programme, nous utiliserons à la place une forme équivalent préfixée (à la Lisp). La notion de schéma de compilation sera au cœur des transformations introduites.
Un schéma de compilation est une règle de réécriture de la forme:
Compile[<phrase1>] --> <phrase2>
où <phrase1> est une énoncé du langage source et <phrase2> est une expression qui contient du code pour la machine cible. On notera les variables sous la forme <x> pour désigner une variable du schéma de compilation (qu'il faut bien évidemment différencier des variables du langage cible).
L'opération de concaténation des expressions cibles s'exprimera à l'aide d'un point virgule ';'.
L'opération de compilation est une opération récursive.
On utilisera fortement le fait de passer les arguments sur la pile. On verra par la suite les problèmes d'optimisation que cela pose et on réfléchira à la manière de les régler.
Notre pseudo-langage Lisp dispose d'arguments notés entre crochets [a1 ,a2,..., an]. L'opérateur @ dans la génération de code indique qu'il faut évaluer l'expression qui suit.
La machine virtuelle - MV
La machine virtuelle que nous utilisons dispose d'une mémoire (fini, mais suffisement grande afin de ne pas être géné) et de trois registres R0, R1 et R2 et d'une pile. La mémoire est un ensemble fini de N cellules. La première cellule a par définition le numéro 0, la dernière le numéro N-1. On parlera plutôt d'adresse mémoire que de numéro de cellule.
La pile est gérée dans la mémoire. La pile commence à l'adresse indique dans le registre spécial BP (base pointer). A priori, on ne touchera jamais à ce registre. le sommet de pile est indiqué dans le registre spécial SP (stack pointer). La pile est vide quand SP = BP. On a toujours SP >= BP (la pile est montante).
Le compteur de programme est contenu dans un register spécial PC (program counter).
Nous avons donc les registres suivants : R0, R1, R2, BP, SP, PC
Modes d'adressage
Valeur constante
Une valeur constante s'écrit directement précédée par le symbole #. Par exemple :
#50
Correspond à la valeur 50.
Mode direct
D'une façon générale, les instructions qui ont besoin d'accéder à des données vont indiquer comme paramètres l'endroit ou se trouvent ces données. Les registres sont directement indiqués tel quels. Par exemple :
R0, R1 ou R2
Correspond respectivement à :
contenu(R0), contenu(R1) et contenue (R2)
Les adresses sont indiquées directement. Par exemple :
500
correspond à la valeur contenue dans l'adresse 500 : contenu(500)
Mode indexé
Une adresse calculée par addition d'un déplacement c au contenu d'une registre R, s'écrit sous la forme c(R). Ainsi, l'instruction:
4(R0)
correspond à la valeur contenue à l'adresse : 4 + contenu(R0) c'est-à-dire contenu(4 + contenu(R0))
Mode indirect
La forme indirecte est préfixée par *. Ainsi, l'instruction :
*R0
correspond à la valeur contenue à l'adresse contenu(R0) c'est-à-dire contenu(contenu(R0)). On a aussi :
*500
qui correspond à la valeur contenue à l'adresse contenue à l'adresse 500 c'est-à-dire contenu(contenu(500))
Mode indirect indexé
Il s'agit de la forme indirecte du mode indexée. Ainsi, l'instruction:
*4(R0)
correspond à la valeur contenue à l'adresse contenu(4 + contenu(R0)) c'est-à-dire contenu(contenu(4 + contenu(R0) + 4)))
Etiquettes et variables globales
Ce type symbole est inséré dans le code pour référencer un adresse particulière. On suppose que la machine virtuelle dispose d'une table <étiquette, adresse> qui permet de retrouver l'adresse correspondant à une étiquette donnée. En précédant une étiquette par le caractère @, on fait référence à son adresse. Par exemple :
@ETIQ
correspond à l'adresse ou se trouve l'étiquette ETIQ.
D'une façon similaire, les variables globales sont référencées comme des étiquettes. Il s'agit d'étiquettes qui se trouvent à un endroit définis à l'avance dans la mémoire. Par exemple, les variables peuvent commencer à l'adresse 0. Par exemple, nous avons les variables globales A, B et C :
On a donc :
|
 @C @C |
l'adresse de C --> 0002 |
|
*@C |
le contenu de l'adresse de C --> -250 |
Instructions
Les instructions ont soit 0, 1 ou 2 paramètres. Sauf indication contraire tous les modes d'adressage sont possibles. En général, il s'agit de la source <src> et de la destination <dest>.
Instructions de base
 MOVE <src> <dest>
Charge <src> dans <dest>
Les différents modes d'adressage présentés ci-dessus peuvent être utilisés. Par exemple :
|
MOVE #50 R0 |
charge la constante 50 dans R0 |
|
MOVE R0 R1 |
recopie le contenu de R0 dans R1 |
|
MOVE R0 500 |
charge le contenu de R0 à l'adresse 500 |
|
MOVE R0 *R1 |
charge le contenu de R0 en mémoire à l'adresse contenue dans R1 |
|
MOVE *R0 *R1 |
charge le contenu de la case mémoire contenue en R0 à l'adresse contenue dans R1 |
ADD <src> <dest>
Ajoute <src> à <dest>, le resultat se trouve dans <dest>.
Par exemple :
|
|
ADD 4(R0) *12(R1) |
|
a pour effet de ranger la valeur contenu(contenu(12 + contenu(R1))) + contenu(4 + contenu(R0)) dans la destination *12(R1).
SUB <src> <dest>
Soutrait <src> à <dest>, le resultat se trouve dans <dest>.
Par exemple :
|
|
SUB 4(R0) *12(R1) |
|
a pour effet de ranger la valeur contenu(contenu(12+contenu(R1)))-contenu(4+contenu(R0)) dans la destination *12(R1).
MULT <src> <dest>
Multiplie <src> à <dest>, le resultat se trouve dans <dest>.
|
|
MULT 4(R0) *12(R1) |
|
a pour effet de ranger la valeur contenu(contenu(12 + contenu(R1))) * contenu(4 + contenu(R0)) dans la destination *12(R1).
DIV <src> <dest>
Divise <dest> par <src>, le resultat se trouve dans <dest>.
|
|
DIV 4(R0) *12(R1) |
|
a pour effet de ranger la valeur contenu(contenu(12 + contenu(R1))) / contenu(4 + contenu(R0)) dans la destination *12(R1).
INCR <dest>
Incrémente <dest> de 1
Par exemple :
|
|
INCR *12(R1) |
|
a pour effet de ranger la valeur contenu(contenu(12 + contenu(R1))) + 1 dans la destination *12(R1).
Cette instruction est équivalente à (ADD #1 <dest>) qui suit, mais elle potentiellement plus efficace.
DECR <dest>
Décrémente <dest> de 1
Par exemple :
|
|
DECR *12(R1) |
|
a pour effet de ranger la valeur contenu(contenu(12+contenu(R1)))-1 dans la destination *12(R1).
Cette instruction est équivalente à (SUB #1 <dest>) qui suit, mais elle potentiellement plus efficace.
Avec ces instructions, nous sommes capables d'écrire les instructions de pile.
Instructions de pile
PUSH <src>
Pousse sur la pile le contenu de <src>.
Le code qui suit est équivalent à
|
|
INCR SP
MOVE <src> *SP |
on incrémente SP
on met <src> à la nouvelle adresse de SP |
POP <dest>
Depile le sommet de pile, et met l'information dans <destination>.
Le code qui suit est équivalent à
|
|
MOVE *SP <dest>
DECR SP |
on met le contenu de l'adresse de SP dans <dest>
on décrémente SP |
Instructions de saut
JMP <dest>
Saute à l'adresse <dest>.
Le code qui suit est équivalent à
|
|
MOVE <dest> PC |
on affecte le compteur de programme avec <dest> |
JSR <etiq>
Saute à l'adresse de l'étiquette <etiq>. Empile l'adresse de retour sur la pile. On revient à l'instruction qui suit le saut avec l'instruction RTN
Le code qui suit est équivalent à JSR <etiq> :
|
|
PUSH PC
JMP @<etiq> |
on pousse l'adresse courante sur la pile
on saute |
RTN
Saute à l'adresse contenue en sommet de pile. Supprime le sommet de pile.
Le code qui suit est équivalent à RTN :
|
|
MOVE *SP R0
DECR SP
JMP *R0
|
adresse présente sur la pile --> R0
on décrémente SP
saut à adresse contenue dans RO |
JL, JEQ, JG, JLE, JGE, JNE <src> <dest>
Saute à l'adresse <dest> si <src> est respectivement plus petit, égal, plus grand, plus petit ou égal, plus grand ou égal ou non égal à 0.
Instructions diverses
NOP
Instruction vide, ne fait rien
HALT
Termine l'execution de la machine virtuelle. Cette instruction doit au moins suivre la dernière ligne de code valide.
Schémas de compilation
Expressions constantes
Les expressions constantes seront empilées en plaçant les valeurs intermédiaires sur la pile en transformant les expressions sous une forme préfixée.
|
Compile[<e1>] ;
PUSH R0 ;
Compile[<e2>] ;
PUSH R0 ;
CompileOp[<op>] |
|
On supposera que les résultats de toutes les opérations sont passées dans le registre R0. Il s'agit d'une convention ; une autre pourrait être choisie.
La compilation d'un opérateur primitif passe généralement par l'appel à une bibliothèque de primitives (calculs de flottants, calculs d'entiers longs, ...) par l'intermédiaire de l'instruction d'appel JSR <prim>. Dans ce cas CompileOp a la forme suivante:
CompileOP[<op>] -->
|
JSR @<op> |
|
Afin que ce mécanisme fontionne, il faut précéder chaque procédure (ou fonction) par un en-tête contenant son étiquette.
Si <op> est en plus une fonction prédéfinie de la machine virtuelle (par exemple la fonction +), on peut la compiler ainsi :
CompileOp[+] -->
Ce code remplace l'appel JSR @+ .
En fait, dans le cas de Lisp on ne sait pas si l'opérateur est effectivement primitif ou non car on ne connaît pas le type des expressions. Cela changera avec l'introduction des types et donc on doit compiler les primitives en faisant appel à une bibliothèque de procédures primitives.
Les constantes sont directement placées dans le registre A0 :
CompileCste[<cste>] -->
|
MOVE #<cste> R0 |
|
Les variables globales sont traitées par utilisation de l'accès direct à une case mémoire : MOV @<var> A0
CompileVarg[<varg>] -->
|
MOVE *@<varg> R0 |
|
Exemple : Compiler l'expressions suivante: ((a + 4) * 2) * (3 - b) et en supposant que a et b sont des variables globales. Soit soit forme préfixée (* (* (+ 4 a) 2) (- 3 b))
|
Compile[(* (* (+ 4 a) 2) (- 3 b))] -->
Compile[(* (+ 4 a) 2)] -->
Compile[(+ 4 a)] -->
CompileCste[4] ;
PUSH R0 ;
CompileVarg[a] ;
PUSH R0 ;
CompileOp[+] ;
CompileCste[4] --> MOVE #4 R0
CompileCste[2] --> MOVE #2 R0
Compile[(- 3 b)] -->
CompileCste[3] ;
PUSH R0 ;
CompileVarGlob[b] ;
PUSH R0 ;
CompileOp[-] ;
CompileCste[3] --> MOVE #3 R0
CompileVarg[b] --> MOVE *@b R0
CompileOp[-] --> JSR @+
CompileOp[*] --> JSR @*
|
|
Si on remet tout ça dans l'ordre on obtient : Compile[(* (* (+ 4 a) 2) (- 3 b))] -->
|
|
MOVE #4 R0
PUSH R0
MOVE *@a R0
PUSH R0
JSR @+
PUSH R0
MOVE #2 R0
PUSH R0
JSR @*
PUSH R0
MOVE #3 R0
PUSH R0
MOVE *@b R0
PUSH R0
JSR @-
PUSH R0
JSR @*
|
|
Lorsqu'on ne fait pas appel à des sous-programmes et qu'on compile les appels à +, - et * directement dans la machine, cela donne :
|
|
MOVE #4 R0
PUSH R0
MOVE *@a R0
PUSH R0
POP R1
POP R0
ADD R1 R0
PUSH R0
MOVE #2 R0
PUSH R0
POP R1
POP R0
MULT R1 R0
PUSH R0
MOVE #3 R0
PUSH R0
MOVE *@b R0
PUSH R0
POP R1
POP R0
SUB R1 R0
PUSH R0
POP R1
POP R0
MULT R1 R0
|
à la place de JSR @+
à la place de JSR @*
à la place de JSR @-
à la place de JSR @* |
Fonctions de tests
En général, les procédures de tests se compilent comme les opérateurs arithmétiques (sauf quand les tests peuvent être effectués par la machine cible et qu'ils se situent dans une structure de contrôle telle qu'un 'if').
Exemple : (a > 4)
|
Compile[(> a 4)] -->
CompileVarg[a] ; --> MOVE *@a R0
PUSH R0 ;
CompileCste[4] ; --> MOVE #4 R0
PUSH R0 ;
CompileOp[>] --> JSR @>
|
|
Soit :
|
MOVE *@a R0
PUSH R0 ;
MOVE #4 R0
PUSH R0 ;
JSR @>
|
|
Les fonction booléennes retournent 0 (faux) ou 1 (vrai) comme valeurs.
Affectation de variables globales
En général, les procédures de tests se compilent comme les opérateurs arithmétiques (sauf quand les tests peuvent être effectués par la machine cible et qu'ils se situent dans une structure de contrôle telle qu'un 'if').
Compile[(setf <var> <expr>)] -->
|
Compile[<expr>] ;
MOVE R0 @<var> |
|
Par exemple, pour (setf a 533), nous avons :
|
|
MOVE #533 R0
MOVE R0 @a |
|
L'état de la mémoire après exécution est :
Note : le code précédent qui pourrait s'optimiser :
|
|
MOVE #533 @a r |
|
Mais, une telle optimisation n'est immédiatement possible, si on a (setf a (+ a 5))
Structures de contrôles
Séquence
La structure de séquence s'exprime simplement comme la concaténation de la compilation des instructions se situant dans la séquence.
|
Compile[<expr1>] ;
Compile[<expr2>] ;
…
Compile[<exprn>] ;
|
|
Si alors sinon
Les structures de contrôles classiques (conditionnelles et boucles) doivent gérer des étiquettes.
|
soit
etiq-sinon = etiq()
etiq-fin = etiq()
Compile[<test>] ;
JEQ R0 @etiq-sinon ;
Compile[<alors>] ;
JMP @etiq-fin ;
etiq-sinon ;
Compile[<sinon>];
etiq-fin ;
|
si R0 = 0 alors test faux |
Par exemple : (if (< a 5) 1 2)
Boucle "tant que"
Le 'tant que' utilise une technique semblable.
Par exemple : (while (< a 5) (setf a (+ a 2)))
Boucle "pour"
Le 'pour' u est plus complexe (for (i 0 n) <expr>). Deux cas se présentent. Soit la valeur finale est une constante et on n'a besoin de la calculer qu'une fois (c'est le cas général - cas 1), soit la valeur finale peut évoluer au cours de la boucle et il faut alors la recalculer systématiquement (cas 2).
Cas 1 : <expr-fin> n'est calculée qu'une seule fois
Compile[(for (<var> <expr-init> <expr-fin>) <expr>)] -->
Par exemple : (for (i 0 10) (setf a (/ a 2)))
01
02
03
|
BOUCLE1
FIN1
|
MOVE
|
|
Cas 2 : <expr-fin> est calculée à chaque tour
|
soit
etiq-boucle = etiq()
etiq-fin = etiq()
Compile[<expr-init>] ;
MOVE R0 @<var> ;
etiq-boucle
Compile[<expr-fin>] ;
MOVE R0 R1 ;
MOVE @<var> R0 ;
SUB R0 R1 ;
JLE R1 @etiq-fin ;
Compile[<expr>] ;
INCR @<var> ;
JMP @etiq-boucle ;
etiq-fin |
<expr-init> --> <var>
<expr-fin> est recalculé
<expr-fin> --> R1
R1 - R0 --> R1
on incrémente <var>
|
Par exemple : (for (i 0 (+ a 1)) (setf a (/ a 2)) )
01
02
03
|
BOUCLE1
FIN1
|
MOVE
|
|
Sous-programmes
Les sous-programmes se trouvent à deux endroits :
- Dans la déclaration du sous-programme
- Lors de son utilisation (l'appel)
Compilation d’une déclaration de sous-programme
Pour l’instant on compile les sous-programmes sans paramètres ni variables locales. Une déclaration d’un sous-programme s’exprime ainsi :
Compile[(defun <proc> <expr>)] -->
où <expr> est généralement de la forme (progn <expr1> .. <exprn>)
|
<proc>
Compile[<expr>] ;
RTN
|
l’etiquette du sous-programme |
Compilation d’un appel de sous-programme
L’appel d’un sous-programme s’exprime ainsi :
|
JSR @<proc>
|
|
Remarque : cela montre la simplicité de la définition des sous-programmes. En fait le problème principal se situe non pas dans les sous-programmes, mais dans les variables locales et les paramètres passés en argument.
Paramètres et variables locales
De nombreuses techniques peuvent être utilisées pour traiter les paramètres des procédures. La première, qui est celle employée initialement par Fortran, consiste à réserver des variables globales dans chaque procédure. Mais elle ne permet pas la récursivité. Les autres utilisent la pile.
Passage de paramètres à la Fortran
Déclaration d'un sous-programme :
Par exemple : (for (i 0 (+ a 1)) (setf a (/ a 2)) )
01
02
03
|
BOUCLE1
FIN1
|
MOVE
|
|
Appel d'un sous-programme :
Compile[(<proc> <expr1> .. <exprn>)] -->
Par exemple : (for (i 0 (+ a 1)) (setf a (/ a 2)) )
01
02
03
|
BOUCLE1
FIN1
|
MOVE
|
|
Problèmes :
1) pas de récursivité possible ;
2) l’accès aux valeurs passées en argument lors de la compilation du corps de la procédure. Comment y accéder ?
Par exemple pour 1, considérons le code Lisp suivant :
(defun foo (x)
(if (= x 0)
1
(+ 1 (foo (- x 1))
))
(foo 5)
Réponse : pour 2), on peut utiliser un environnement. Un environnement est une suite de couples (symbole, valeur), que l’on notera {(s1,v1),..,(sk,vk)} et que l’on manipulera avec les deux fonctions :
at[env, s] == v si s est un symbole de l’environnement et une erreur sinon.
atput[env,sj,v’j] ==
env’ = env + {(sj,v’j)} si sj n’est pas un symbole de l’environnement et
env - {(sj,vj)} + {(sj,v’j)} si (sj,v’j) était dans env.
On ajoutera donc un argument à la fonction Compile[<expr>, <env>] qui exprime que l’expression se compile dans l’environnement <env>. Nous verrons par la suite que nous ajouterons d’autres variables à la fonction Compile. Dans toutes les expressions que nous avons compilé pour l’instant, cela ne change rien : on reporte simplement la variable d’environnement inchangée.
Ainsi, la compilation d’expression s’écrit maintenant ainsi :
Par exemple : ?
01
02
03
|
BOUCLE1
FIN1
|
MOVE
|
|
Lors de la compilation du corps d’une procédure, nous allons passer à la fois les noms des variables ainsi que les adresses (les étiquettes) des variables locales :
Compile[(defun (<proc> <x1> .. <xn>) <expr>),<env>] -->
où <op> est une opération primitive
|
soit
debut_proc = etiq(debut_, <proc>)
var_x1 = etiq(v, <proc>, _, <x1>)
...
var_xn = etiq(v, <proc>, _, <xn>)
<nenv> = {(<x1>, @var_x1), .., (<xn>, @var_xn)}
<proc> ;
JMP @debut_proc
var_x1 0 ;
...
var_xn 0 ;
debut_proc
POP R2 ;
POP R0 ;
MOVE R0 @var_xn ;
...
POP R0
MOVE R0 @var_x1 ;
PUSH A2
Compile[expr,<nenv>] ;
RTN |
|
Par exemple :
01
02
03
|
BOUCLE1
FIN1
|
MOVE
|
|
Accès aux variables locales
Lors de la compilation des variables, ce qui s’exprimait auparavant ainsi :
Compile[<ident>] -->
|
MOVE @<ident> R0 |
|
se compile maintenant à l’aide des environnements :
Compile[<ident>, <env>] -->
|
MOVE (loc @at[<env>,<ident>]) R0 |
|
01
02
03
|
BOUCLE1
FIN1
|
MOVE
|
|
Exemple
01
02
03
|
BOUCLE1
FIN1
|
MOVE
|
|
Valeur de retour
On notera qu’il n’y a strictement rien à faire pour que les procédures retournent un résultat. Le dernier résultat se trouve dans R0 lors de la sortie de la procédure. Si l’on désire avoir une instruction de type return comme en C, on écrira simplement :
Compile[(return <expr>), <env>] -->
|
Compile[<expr>, <env>] ;
RTN |
|
Passages de paramètres par la pile
On utilise la pile pour le passage de paramètres. Le principe consiste à laisser les variables sur la pile. On obtient alors :
Compile[(defun <proc> (<x1> … <xn>) <expr>), <env>] -->
|
debut_proc
Compile[<expr>, <env>] ;
RTN |
|
L’appel de procédure se fait simplement comme dans l’appel de type Fortran. Problème : comment accéder aux variables locales sur la pile ? Réponse : il faut marquer la pile lors de l’appel des sous-programmes. Il s'agit de la notion de bloc de pile (stack frame).
Il existe de nombreuses formes de bloc de pile, mais elles se ramenent simplement à faire des variantes de celle qui est décrite ci-dessous.
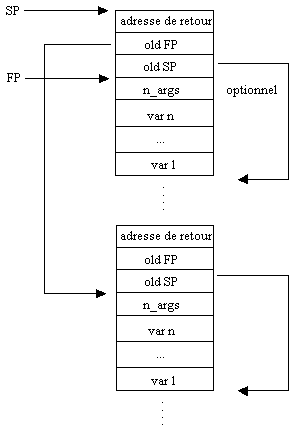
Cela signifie que lors de la compilation d’un appel il faut générer le code suivant :
Compile[(<proc> <expr1> … <exprn>), <env>] -->
Compile[(<proc> <e1> .. <en>),<env>]
?soit n = nombre d’arguments
?®
?Compile[<e1>,<env>] ;
?(PUSH A0)
?Compile[<en>,<env>] ;
?(PUSH A0)
// debut de l’entete d’appel
?(PUSH @n)??// nombre d’arguments
// ce qui se passe ici pourrait être fait dans la procédure
// appelée (technique du link et unlink). Mais, dans ce cas,
// l'adresse de retour se situe juste au dessus de n-args
?(MOV A1 FP)??// on recupere l’ancien FP
?(MOV FP SP)??// le nouvel FP = SP
?(MOV A2 SP)??// on recupere l’ancien SP
?(DIFF A2 A2 @n)
?(DIFF A2 A2 1)?// A2 = SP - (n + 1)
?(PUSH A2)??// sauve l’ancien SP
?(PUSH A1)??// sauve l’ancien FP
// fin de l’entete d’appel
?(JSR <proc>)
// debut de la restauration du contexte d’exécution
?(POP A1)??// recupere l’ancien FP
?(POP A2)??// recupere l’ancien SP
?(MOV FP A1)??// FP est restaure a son ancienne valeur
?(MOV SP A2)??// on a supprime toutes les variables
// fin de la restauration
On récupère les variables sur la pile à l’adresse suivante :
vari ® FP - (n + 1) + i // on compte i à partir de 0
Si on utilise l’instruction (local <reg><n>) qui va chercher le nième élément sur la pile à partir de FP et le place dans <reg>
Ainsi la compilation d’une procédure avec passage de paramètres se compile ainsi:
Compile[(define (<proc> <x1> .. <xn>) <expr>),<env>]
?soit n = nombre de paramètres
?<nenv> = {(<x1>,-(n+1)+1),..,
???? (<xi>,-(n+1)+i),..,
?????(<xn>,-2)} // - 2 car -(n+1)+(n-1) = -2
?®
?<proc> ;?// l’etiquette du sous-programme
???(FENTRY <proc>) ; // ne sert à rien en fait
???Compile[<expr>,<nenv>] ;
???(RTN)
et l’accès aux variables s’écrit ainsi :
Compile[<ident>,<env>] ® (LOCAL A0 @at[<env>,<ident>])
De même l’affectation est donnée par :
Compile[(set! <ident> <expr>), <expr>] ®
?Compile[<expr>, <env>];?
?(SETLOCAL @at[<env>, <ident>] A0)
- Compilation des variables locales
Principe: les variables locales sont sur la pile et "poussent" à l'envers des paramètres.
Ces variables sont introduites par le mot clé Var en Pascal au début d'une procédure où se situent au début d'un "bloc" en C. En Scheme et Lisp ces variables sont introduites par la structure Let. On supposera que les variables locales sont définies une fois pour toute par le mot clé vars au début de la définition d'une procédure.
On supposera qu'il n'est pas possible de définir
(define (f x)
?(vars z y)
?(set! z (1+ x))
?(set! y 0)
(while (> y z)
??...
??(set! y (1+ y))
?))
Compile[(vars <x1> .. <xn>), <env>]
?pour <xi>
??atput[<env>,<xi>,i+2] // le +2 est utilisé pour sauter par
????// dessus les infos laissées sur la pile
?® pour i = 1 to n do
??(PUSH 0)??// réserve de la place pour la variable locale
L'accès aux variables locales se fait ensuite comme pour les paramètres, c'est-à-dire par la règle de compilation suivante:
Compile[<ident>,<env>] ® (LOCAL A0 @at[<env>,<ident>])
- Procédures dans des variables
Certains compilateurs Pascal et C permettent d'avoir des pointeurs sur des procédures et d'utiliser dynamiquement ces procédures. Par exemple:
void f(int x) {..}
main() {
?...
?m = f;
?..
?(m*)(3);
?..
}
De même en Scheme on peut écrire:
(define (f x y)(* x y))
(set! a f)
(a 3 4) ® 12
Principe: si l'on s'aperçoit que l'identificateur réfère à une procédure (mais qu'elle n'a pas été définie ainsi), on compile non pas un appel direct, mais un appel indirect via A0. Les modifications par rapport à un appel direct sont notées en gras:
Compile[(<expr> <e1> ... <en>), <env>] ®
??soit n = nombre d’arguments
?®
?Compile[<e1>,<env>] ;
?(PUSH A0)
?Compile[<en>,<env>] ;
?(PUSH A0)
// debut de l’entete d’appel
?(PUSH @n)??// nombre d’arguments
// insertion de la compilation de <expr>
?Compile[<expr>, <env>]; // Attention: résultat dans A0
?(MOV A1 FP)??// on recupere l’ancien FP
?(MOV FP SP)??// le nouvel FP = SP
?(MOV A2 SP)??// on recupere l’ancien SP
?(DIFF A2 A2 @n)
?(DIFF A2 A2 1)?// A2 = SP - (n + 1)
?(PUSH A2)??// sauve l’ancien SP
?(PUSH A1)??// sauve l’ancien FP
// fin de l’entete d’appel
?(JSR A0)??// appel indirect via A0
// debut de la restauration du contexte d’exécution
?(POP A1)??// recupere l’ancien FP
?(POP A2)??// recupere l’ancien SP
?(MOV FP A1)??// FP est restaure a son ancienne valeur
?(MOV SP A2)??// on a supprime toutes les variables
// fin de la restauration
Remarque: cette modification peut s'appliquer aussi à l'appel direct. C'est généralement ce qui se passe dans les langages faiblement typés, où il est difficile de savoir si la variable est un identificateur correspondant effectivement à la fonction où s'il s'agit d'une variable qui contient une procédure.
- Procédures locales
Compilation des fonctions auxiliaires que l'on ne veut pas définir à l'extérieur d'une procédure. On rencontre ce type de procédure en Pascal, en Ada et en Scheme. Exemple en Scheme:
(define (indice lst x)
(define (indice1 lst x i)
(cond
? ??((null? lst) ())
? ??((equal? (car lst) x) i)
? ??(else (indice1 (cdr lst) x (1+ i)))))
(indice1 lst x 0))
(indice '(a b c d e) 'c) ® 2
(define (f x)
(define (g z)
(set! x (1+ z))
x)
(+ x (g 3)))
(f 5) ® 9
Principe:
- On considère que la procédure interne (par exemple g) dans le deuxième exemple est une variable locale de la procédure.
- On compile l'appel à la procédure locale comme s'il s'agissait d'une procédure passée dans une variable.
- Les variables locales à la procédure interne sont récupérées normalement sur la pile dans un bloc de pile local.
- Les variables globales à la procédure interne, mais locales à la procédure de définition sont accédées au travers du pointeur de frame et on remonte ensuite les blocs de piles jusqu'à aller au bloc de pile de bon niveau.
- Lors de la compilation, on passe un environnement structuré en plusieurs parties. Chaque partie correspond à un niveau d'emboîtement.
La compilation des procédures les plus globales n'est pas modifiée!
Voici la nouvelle compilation des procédures:
Compile[(define (<proc> <x1> .. <xn>) <expr>),<env>] et <env> ¹ ()
?atput[<env>,<proc>,paramNumber[]] // on ajoute une variable
??// local à l'environnement englobant.?
?soit n = nombre de paramètres
???<nenv> = {{(<x1>,-(n+1)+1),..,
???? (<xi>,-(n+1)+i),..,
?????(<xn>,-2)}
?????<env>}?// emboitement des environnement
?®
?<proc> ;?// l’etiquette du sous-programme
???(FENTRY <proc>) ; // ne sert à rien en fait
???Compile[<expr>,<nenv>] ;
???(RTN)
Le changement principal se situe dans l'accès aux variables:
Compile[<ident>,<env>]
?et <ident> Î 1er élément de <env> // variable locale
?®
???(LOCAL A0 @at[<env>,<ident>])
Compile[<ident>,<env>]
?et <ident> Ï <env> // variable purement globale
?®
???(MOV A0 @<ident>)
Et voilà le code de recherche d'un élément dans les blocs de piles englobant!
Compile[<ident>,<env>]
?et <ident> Ï 1er élément de <env> // variable locale/globale
?et <ident> Î <env> (élément suivant)
?soit var_x = at[<env>, <ident>] et
???n = niveau d'emboitement de <ident>
?®
??(MOV A1 ?(FP+1))?// on prend l'ancien FP (indirect indexé)
??(MOV A2 @n)
?recherche
??(JEQ A2 0 trouve)
??(MOV A1 (A1+1))?// recupere les FP
??(SUB A2 A2 1)??// on decremente A2
??(JMP recherche)
?trouve
??(MOV A2 FP)??// on sauve FP
??(MOV FP A1)??// FP prend la valeur du FP "global"
??(LOCAL A0 @var_x)
??(MOV FP A2)??// FP reprend sa valeur
- Structures de données
Compilation des structures de données.
Plusieurs classes de données:
- Les données statiques qui sont allouées par le compilateur.
- Les données semi-dynamiques qui sont allouées sur la pile lors de l'appel d'une procédure.
- Les données dynamiques qui sont allouées à la demande du programmeur (instruction new en Pascal et malloc en C, objets en Ada et Smalltalk).
- Tableaux
- Compilation statique
- Déclaration
On réserve de la place dans une zone de données.
Var A : Array[1..6] of Integer;
?sera transformé en:
A:?word 0
?word 0
?...
?word 0
Compile[<nom> : Array [1..<n>] of Integer, <env>]
?et <env> = nil // environnement global
?®
?<nom> word 0;?
?for i = 1 to <n>-1 do
? ??word 0
- Accès
Compile[<tab>[<expr>],<env>] ®
?Compile[<expr>, <env>];
?(MOV A1 <tab>); // recupere l'adresse de base
?(ADD A1 A1 A0); // ajoute l'offset
?(MOV A0 (A1)); // recherche indirecte de l'information.
Compile[<tab>[<expr1>]:= <expr2>,<env>] ®
?Compile[<expr1>, <env>];
?(PUSH A0)
?Compile[<expr2>, <env>];
?(MOV A1 <tab>); // recupere l'adresse de base
?(POP A2);?// recupere la valeur de l'offset
?(MOV A1 A1 A2); // ajoute l'offset
?(MOV (A1) A0);?// sauvegarde indirecte
- Compilation semi-dynamique
- Déclaration
On réserve de la place sur la pile lors de l'allocation des variables locales.
Compile[<nom> : Array [1..<n>] of Integer, <env>] et <env> local
?®
?for i = 1 to <n> do
??(PUSH 0)
- Accès
Les accès s'effectuent comme précédemment. Seul change l'adresse de base qui se trouve sur la pile.
En lecture:
Compile[<tab>[<expr>],<env>] ®
?Compile[<expr>, <env>];
?(LOCAL A1 @at[<env>,<tab>])?; // recupere l'adresse de base
?(ADD A1 A1 A0); // ajoute l'offset
?(MOV A0 (A1)); // recherche indirecte de l'information.
Compile[<tab>[<expr1>]:= <expr2>,<env>] ®
?Compile[<expr1>, <env>];
?(PUSH A0)
?Compile[<expr2>, <env>];
?(LOCAL A1 @at[<env>,<tab>])?; // recupere l'adresse de base
?(POP A2);?// recupere la valeur de l'offset
?(MOV A1 A1 A2); // ajoute l'offset
?(MOV (A1) A0);?// sauvegarde indirecte
- Compilation dynamique
Var P: ^Array[1..6] of Integer;
Compile[new(P), <env>]
?s = taille du type de P
? ®
?(ALLOCATE @s);?// general. un appel a une routine systeme
?(MOV (loc <P>) <A0>) // si P est une variable globale.
- Accès
Les accès s'effectuent comme précédemment. Seul change l'adresse de base qui se trouve dans la variable P. La différence se situe dans l'appel indirect de la variable (opérateur ^ en Pascal et * en C).
En lecture:
Compile[<p>^[<expr>],<env>] ®
?Compile[<expr>, <env>];
?(MOV A1 <P>)
?(MOV A1 (A1)); // recupere l'adresse de base (via l'indirect.)
?(ADD A1 A1 A0); // ajoute l'offset
?(MOV A0 (A1)); // recherche indirecte de l'information.
Compile[<tab>[<expr1>]:= <expr2>,<env>] ®
?Compile[<expr1>, <env>];
?(PUSH A0)
?Compile[<expr2>, <env>];
?(MOV A1 <P>)
?(MOV A1 (A1)); // recupere l'adresse de base (via l'indirect.)
?(POP A2);?// recupere la valeur de l'offset
?(MOV A1 A1 A2); // ajoute l'offset
?(MOV (A1) A0);?// sauvegarde indirecte
- Record
On gère les record comme des tableaux. Seul change le fait que les valeurs sont de types différents et donc (normalement) de taille différente.
R: Record a: Integer; b: Integer end;
R:?word 0?// A
?word 0?// B
C'est le compilateur qui a la charge de faire le lien entre les noms de champs et l'indice de la valeur
Compile[<rec>:Record <champ1>:<type1>;..;<champ1>:<type1> end,
?? <env>] et <env> = nil
?soit taille = taille de <rec>
?®
?<nom> word 0;?
?for i = 1 to <taille>-1 do
? ??word 0
Suppose que la table des symbole dispose des informations nécessaires ensuite pour transformer les noms des champs en offsets.
- Objets
Même structure que pour les records.
|