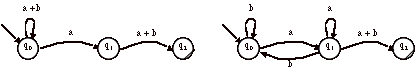Chapitre 2
2.1 Automates d'états finis
Définition
informelle
Notations
Reconnaissance
d'un mot
Définition
formelle des automates finis déterministes
Automates
finis non-déterministe
Automates
avec e-transition
Équivalences
d'automates
2.2 Transformation d'une expression régulière en un automate
Propriété
Cas
de base
Récurrence
. Élimination
des e-transitions
2.3 Transformation d'un automate en une expression régulière
Par
réduction d'automates
Par
résolution d'équations
2.4 Déterminisation et Minimisation
Méthode
de déterminisation
Relation
d'équivalence sur les langages réguliers
2.5 Autres opérations sur les automates
Automate
complémentaire
Automate
miroir
Intersection
de deux automates
2.6 Conclusion
Dans ce chapitre, nous présentons et étudions la classe de machines abstraites que sont les automates à états finis réguliers. Ces automates sont strictement équivalents en puissance aux langages réguliers. Ils constituent le niveau le plus faible des machines et langages qui nous étudierons.
Après avoir présenté les différentes variations possibles sur les automates réguliers, nous abordons, en détail, la transformation d’une expression régulière vers un automate. Elle est présentée selon deux approches distinctes quoique strictement équivalentes : la réduction d’automates et la résolution d’équations. Certains problèmes sur les expressions régulières peuvent être aisément résolus en passant par les automates les reconnaissant. De façon similaire, nous présentons ensuite la transformation inverse, d’un automate en une expression régulière.
La « déterminisation » permet de passer d’un automate non-déterministe, souvent facile à trouver, à son équivalent déterministe. Cette transformation se base sur la définition d’une relation d’équivalence sur les états.
Enfin, plusieurs opérations sur les automates sont introduites : intersection, complémentaire, image miroir. Ces opérations sont en général faciles sur les automates mais difficiles à réaliser sur les expressions régulières.
1. Automates d’états finis
1.1. Définition informelle
Un automate effectue un ensemble d’actions et fournit un résultat. En ce sens un s’agit d’un algorithme. L’objet de cette classe d’algorithmes est de reconnaître si un mot donné appartient à un langage régulier que décrit l’automate.
L’automate d’états finis (déterministe ou non) est composé de :
· Une bande (infinie) de lecture comportant des cases. Chaque case contient un caractère de V ;
· Une tête de lecture désignant une case particulière ;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
· Un dispositif de contrôle pouvant prendre un nombre finis d’états. Ce dispositif peut être dans l’état 0, 1, 2, 3, …
· L’automate dispose d’une table de transition (son programme). Cette table de transition précise le changement d’état de l’automate :
|
|
a |
b |
c |
… |
s |
… |
|
® 0 |
1 |
- |
2 |
|
|
|
|
¬ 1 |
- |
1 |
|
|
|
|
|
2 |
1 |
2 |
|
|
|
|
|
… |
|
|
|
|
|
|
|
q |
|
|
|
|
q’ |
|
|
… |
|
|
|
|
|
|
L’automate étant dans l’état q. Sa tête de lecture désigne une case contenant le symbole s. Alors :
· L’automate passe dans l’état q’ ;
· Sa tête de lecture se déplace sur la case suivante (celle située immédiatement à droite de la case de s).
Parmi l’ensemble des états de l’automate, on distingue les états initiaux (états d’entrée) et les états finals (états de sortie). Un état initial peut aussi être final. En général, on s’ « arrange » pour n’avoir qu’un seul état initial.
On note L(A) l’ensemble des mots reconnus par l’automate A. Pour les automates d’états finis , cet ensemble est un langage régulier.
1.2. Notations
Une notation graphique équivalente à la notation tabulaire
est proposée. Dans le reste de ce cours on tendra à privilégier la notation
graphique plus immédiatement lisible. Toutefois, il est parfois nécessaire de
passer de l’une à l’autre.
La notation tabulaire est celle utilisée par les
algorithmes de construction et de transformation d’automates.
 > Par
exemple, les deux représentations ci-dessous sont équivalentes :
> Par
exemple, les deux représentations ci-dessous sont équivalentes :
|
|
a |
b |
c |
|
® 0 |
1 |
- |
2 |
|
¬ 1 |
- |
1 |
- |
|
2 |
1 |
2 |
- |
<
Sous la forme tabulaire, on indique par une flêche
entrante (®) les états initiaux. On indique par une flêche sortante (¬) les état finaux. Les transitions inexistantes laissent
des cases vides (-).
Sous la forme graphique, on indique les états initiaux à
l’aide d’une flêche sans origine. Les états finaux sont barrés.
Une notation fonctionelle est aussi parfois utilisée.
Celle-ci est proche de la définition formelle. Elle introduit une fonction de
transition : d(un état, un élément de V) = un état.
> Pour l’automate
ci-dessus, on a la notation fonctionnelle suivante :
V = {a, b ,c}
états = {0, 1, 2} états
initiaux = {0} états
finals = {1}
d(0, a) = 1, d(0, c) = 2, d(1, b) = 1, d(2, a) = 1, d(2, b) = 1
<
On remarquera qu’une transition inexistante est
équivalente à une transition f, et que l’automate précédent
pourrait être (beaucoup plus lourdement) écrit :
>
|
|
a |
b |
c |
|
® 0 |
1 |
f |
2 |
|
¬ 1 |
f |
1 |
f |
|
2 |
1 |
2 |
f |
<
Un automate est dit « bien formé » s’il vérifie les conditions suivantes :
·
il n’existe aucune transition portant f ;
· tous les états sont ateignables à partir d’un état initial.
Sauf indication contraire on ne considèrera que des automates bien formés.
Un automate est dit « saturé » s’il vérifie les conditions suivantes :
· il n’existe aucune transition portant f ;
· de chaque état partent au moins une transition pour chaque élément de V.
1.3. Reconnaissance d’un mot
Un mot est reconnu par l’automate si, à partir de la position initiale (automate dans l’état initial, et la tête de lecture désignant le premier caractère de ce mot), l’automate parcours le mot en entier et termine son parcours dans un état final.
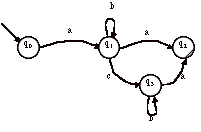
> Par exemple, soit l’automate suivant :
|
|
a |
b |
c |
|
® 0 |
1 |
- |
- |
|
1 |
2 |
1 |
3 |
|
¬ 2 |
- |
- |
- |
|
3 |
2 |
3 |
|
Sans le démontrer formellement, nous pouvons « deviner » que cet automate reconnaît le langage décrit par l’expression régulière :
ab*(a + cb*a)
Faisons fonctionner l’automate sur le mot « abba »
1)
|
|
|
|
a |
b |
b |
a |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
2)
|
|
|
|
a |
b |
b |
a |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
3)
|
|
|
|
a |
b |
b |
a |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
4)
|
|
|
|
a |
b |
b |
a |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
5)
|
|
|
|
a |
b |
b |
a |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
L’automate a parcouru complètement le mot et il s’arrête dans l’état final q2. Le mot est donc reconnu.
Essayons pour le mot « abab » :
1)
|
|
|
|
a |
b |
a |
b |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
2)
|
|
|
|
a |
b |
a |
b |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
3)
|
|
|
|
a |
b |
a |
b |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
4)
|
|
|
|
a |
b |
a |
b |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
La transition (q2, b) n’est pas définie. L’automate s’arrête sans avoir parcouru le mot. Le mot n’est donc pas reconnu.
Essayons pour le mot « abc» :
1)
|
|
|
|
a |
b |
c |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
2)
|
|
|
|
a |
b |
c |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
3)
|
|
|
|
a |
b |
c |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
4)
|
|
|
|
a |
b |
c |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
L’automate a parcouru complètement le mot, il s’arrête donc dans l’état q3 qui n’est pas un état final. Le mot n’est donc pas reconnu.
<
Nous avons deux cas où l’automate refuse un mot (c’est-à-dire que le mot n’appartient pas au langage reconnu par l’automate) :
· soit, avant d’avoir parcouru complètement le mot, l’automate se trouve bloqué dans un état non final ;
· soit, après avoir parcouru complètement le mot, l’automate ne se trouve pas dans un état final.
1.4. Définition formelle des automates finis déterministes (AFD)
Un automate d’état fini déterministe est un quintuplet :
Adet= (VT, Q, Q0, F, m)
où
Q est un ensemble fini d’états ;
Q0 Î Q ;
F Ì Q ;
VT est un ensemble fini de symboles – le vocabulaire ;
m est une fonction de transition : Q ´ VT ® Q ;
La fonction de transition induit une relation binaire (notée a) sur l’ensemble Q ´ VT* de la manière suivante :
(q, sw) a (q’, w) Û m(q, s) = q’
Soit a* l’extension réflexive et transitive de la relation a.
" q Î Q, w Î V* (q, w) a* (q, w)
" q, q’, q’’ Î Q, w, w’, w’’ Î V*
(q, w) a (q’, w’) Ù (q’, w’) a* (q’’, w’’) Þ (q, w) a* (q’’, w’’)
Alors w Î L(A) si et seulement si :
$ q Î F : (q0, w) a* (q, e)
Le mot w appartient au langage reconnu par l’automate si il existe un chemin de l’état initial à un état final qui décrit ce mot.
e Î L(A) Û q0 Î F
e est un mot du langage reconnu par l’automate si l’état initial est final.
1.5. Définition formelle des automates finis non déterministes (AFN)
Pour un automate d’état fini non déterministe, la fonction de transition est définie sur des ensembles. On a donc :
Andet= (VT, Q, Q0, F, m’)
où
Q est un ensemble fini d’états ;
Q0 Î Q ;
F Ì Q ;
VT est un ensemble fini de symboles – le vocabulaire ;
m’ est une fonction de transition : Q ´ VT ® Ã(Q) ; Ã(Q) représente les parties de Q.
La relation de transition devient :
(q, sw) a (q’, w) Û q’ Î m(q, s)
> Par exemple, soit l’automate non-déterministe suivant :
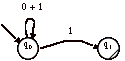
|
|
0 |
1 |
|
® 0 |
0 |
0, 1 |
|
¬ 1 |
- |
- |
Cet automate permet la reconnaissance des mots sur VT = {0, 1} se terminant par 1.
Faisons fonctionner l’automate sur le mot « 01 »
1)
|
|
|
|
0 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
2)
|
|
|
|
0 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
3) À ce stade, nous avons, le choix entre deux possibilités, choisissons la transition vers q0.
|
|
|
|
0 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
Ce fonctionnement rejète le mot.
Réessayons, en choisissant l’autre chemin.
1’)
|
|
|
|
0 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
2’)
|
|
|
|
0 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
3’) Choisissons la transition vers q1.
|
|
|
|
0 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
Ce fonctionnement accepte le mot.
Nous avons mis en évidence une façon d’accepter le mot. Le mot appartient donc à L(A).
<
On remarquera qu’il est souvent plus facile de trouver un automate non-déterministe que déterministe. Nous verrons dans la suite qu’il est possible de « déterminiser » un automate.
4 Construisez l’automate du langage L sur V={a, b} ne contenant que les mots qui se termine par « abb ».
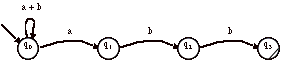 Réponses : L’automate non-déterministe est très simple.
Réponses : L’automate non-déterministe est très simple.
L’expression régulière est également simple :(a+b)*abb. Comment peut-on procéder pour la « deviner » ?
Essayez de construire une version déterministe de l’automate. Que constatez-vous ?
3
On remarquera qu’un automate non-déterministe est souvent plus petit que sa version déterministe. Cependant, son exécution est plus complexe. Il faut en effet se remémorer chaque point de choix et y revenir un cas d’échec.
1.6. Automate avec e-transition
Un automate avec e-transition (eAEF) dispose d’une fonction de transition définie sur VT È {e}. La relation de transition devient donc :
(q, w) a (q’, w) Û q’ Î m(q, e)
(q, sw) a (q’, w) Û q’ Î m(q, s)
> Par exemple, soit l’automate suivant :
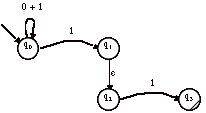
|
|
e |
0 |
1 |
|
® 0 |
- |
0, 1 |
0 |
|
1 |
2 |
- |
- |
|
2 |
- |
- |
3 |
|
¬ 3 |
- |
- |
- |
Faisons fonctionner cet automate sur « 01 »
1)
|
|
|
|
0 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
2)
|
|
|
|
0 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
3) On prend la e-transition qui ne fait pas avancer la tête de lecture sur la bande.
|
|
|
|
0 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
4)
|
|
|
|
0 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]()
Ce fonctionnement accepte le mot.
<
1.7. Équivalences d’automates
La classe des automates d’états finis (AEF) est la plus générale. Les automates finis peuvent être déterministes (AEF-det) ou non déterministe (AEF-ndet). De plus, ils peuvent (ou non) contenir des e-transitions (de façon générale, nous appellerons ce type d’automate des e-automates). Les e-automates sont non-déterministes.
On verra que tous ces types d’automates sont rigoureusement identiques et que l’on peut toujours se ramener, par simplification et « déterminisation » à un AEF-det.
Pour résumer, un automate est considéré comme non-déterministe (au sens large) si au moins une des conditions suivantes est vérifiée :
· Il existe au moins plusieurs transitions t1, t2, … tn portant le même symbole x partant d’un état unique q vers plusieurs états q1, q2, … qn ;
· Il existe au moins une e-transition ;
· Il existe plus d’un état initial.
Autrement dit, s’il existe à un moment donné un point de choix lors de la reconnaissance d’un mot, l’automate n’est pas déterministe. De plus, à chaque étape, le pointeur doit avancer sur la bande de lecture.
4 pour un mot de longueur l appartenant à L(A), A étant déterministe, combien d’étapes sera-t-il nécessaire pour que l’automate le reconnaisse ?
Que peut-on dire pour un mot qui n’appartient pas à L ?
Que peut-on dire si l’automate est saturé ? Que peut-on dire si l’automate n’est pas bien formé ?
3
On remarquera, par ailleurs, que pour tout automate A, on peut créer un automate A’, n’ayant qu’un seul état initial et qu’un seul état final, tel que L(A) = L(A’).
En effet, si on a plusieurs états finals, il suffit de créer un nouvel état final F et de relier à l’aide de e-transitions les états finals d’origine à cet état F.
De façon analogue, si on a plusieurs états initiaux, il suffit de créer un nouvel état initial I et de relier à l’aide de e-transitions cet état I aux états initiaux d’origine.
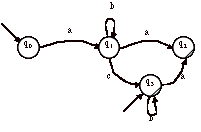
> Par exemple, soit l’automate A suivant :
|
|
a |
b |
c |
|
® 0 |
1 |
- |
- |
|
1 |
2 |
1 |
3 |
|
¬ 2 |
- |
- |
- |
|
® ¬ 3 |
2 |
3 |
|
On peut « deviner » que le langage reconnu par cet automate pourrait être noté par l’expression régulière :
ab*a + ab*cb* + ab*cb*a + b* + b*a
= ab*a + ab*cb*(e + a) + b*(e + a)
= ab*a + (ab*c + e)b*(e + a)
L’automate ayant une structure simple, il est possible de suivre (sans en oublier) les différents chemins. Une telle méthode n’est pas toujours aisée si l’automate est plus touffu.
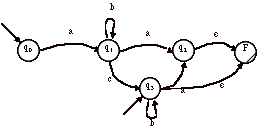
1) Soit A’ l’automate obtenu par ajout d’un état final unique :
|
|
e |
a |
b |
c |
|
® 0 |
|
1 |
- |
- |
|
1 |
|
2 |
1 |
3 |
|
2 |
F |
- |
- |
- |
|
® 3 |
F |
2 |
3 |
|
|
¬ F |
- |
- |
- |
|
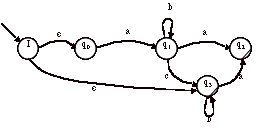
2) Soit A’’, l’automate obtenu par ajout d’un état initial unique :
|
|
e |
a |
b |
c |
|
® I |
0, 3 |
- |
- |
- |
|
0 |
|
1 |
- |
- |
|
1 |
|
2 |
1 |
3 |
|
¬ 2 |
|
- |
- |
- |
|
¬ 3 |
|
2 |
3 |
|
3) On obtient donc l’automate A’’’ par combinaisons de A’ et A’’ :
|
|
e |
a |
b |
c |
|
® I |
0, 3 |
- |
- |
- |
|
0 |
|
1 |
- |
- |
|
1 |
|
2 |
1 |
3 |
|
2 |
F |
- |
- |
- |
|
|
F |
2 |
3 |
|
|
¬ F |
|
|
|
|
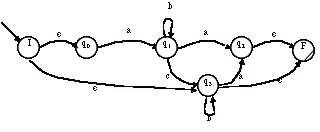
L’automate ainsi obtenu peut éventuellement être simplifié.
Il n’y a aucune transition entrante dans l’état initial et aucune transition sortante de l’état final. <
4 Exercice : vérifier qu’à chaque étape le langage reconnu par l’automate reste inchangé.
3
Dans le cas d’un automate disposant d’un état initial et d’un état final unique, il est parfois pratique de simplifier la notation graphique. Cette nouvelle notation permet de « masquer » les détails liés à l’automate pour ne se concentrer que sur son entrée et sa sortie.
Avec L(A) = L(R), un automate A peut se noter comme suit :
![]()
> À partir de l’exemple précédent, on pourra donc avoir :
![]()
<
2. Transformation d’une expression régulière en un automate
2.1. Propriété
Soit la propriété S(n) définie comme suit :
Si R est une expression régulière à n occurrences d’opérateurs et aucune variable comme opérandes atomique (.) alors il existe un e-automate A qui accepte les mots de L(R) et aucune autres. A n’a :
· Qu’un seul état d’acceptation (état final) ;
· Pas d’arc vers son état initial ;
· Pas d’arc issu de son état final.
2.2. Cas de base
Soit la case de base S(0) défini comme suit :
Si n=0 alors R doit être un opérande atomique qui est : soit f, soit e, soit x pour un certain symbole x (x Î V). Pour chacun des trois cas, on peut concevoir un automate à 2 états pour lequel S(0) est vrai :
![]()
![]()
![]()
![]()
2.2. Récurrence
Nous allons supposer que si on a S(n) alors nous avons S(n+1) :
Nous allons créer de nouveaux automates. Pour chaque occurrence de l’expression régulière, on crée un état particulier.
> Par exemple, si l’expression régulière contient 3 a, alors on créera 6 états sur le modèle :
![]()
<
Supposons que S(i) soit vraie pour tout i supérieur ou égal à n ("i £ n). Autrement dit, pour une expression régulière R quelconque avec au plus n occurrences d’opérateurs, il existe un automate satisfaisant à l’hypothèse de récurrence et acceptant tous les mots de L(R) et seulement ceux-là.
Soit R une expression régulière avec (n+1) occurrences d’opérateurs.
On s’intéresse à l’opérateur le plus extérieur, c’est-à-dire, la racine de la structure syntaxique. Alors R est de la forme R1 + R2, ou R1.R2 ou R1*
Dans chacun des trois cas, R1 et R2 ne peuvent comporter plus de n occurrences car l’opérateur situé à la racine de la structure syntaxique ne fait partie ni de R1 ni de R2, et que R a exactement (n+1) occurrences d’opérateurs.
L’hypothèse de récurrence s’applique donc à R1 et R2 dans chacun des trois cas. On peut alors démontrer S(n+1) dans chacun des trois cas.
On remarquera, par ailleurs, que pour tout automate A, on peut créer un automate A’, n’ayant qu’un seul état initial et qu’un seul état final, tel que L(A) = L(A’).
En effet, si on a plusieurs états finals, il suffit de créer un nouvel état final F et de relier à l’aide de e-transitions les états finals d’origine à cet état F.
De façon analogue, si on a plusieurs états initiaux, il suffit de créer un nouvel état initial I et de relier à l’aide de e-transitions cet état I aux états initiaux d’origine.
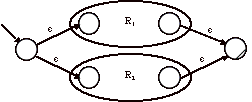 1) R
= R1 + R2
1) R
= R1 + R2
L’état initial associé à R comporte des e-transitions vers les états initiaux des automates associés à R1 et R2. Les anciens états initiaux deviennent des états ordinaires.
Les états finals (d’acceptation) de ces deux automates deviennent des états ordinaires et on ajoute des e-transitions vers l’état d’acceptation du nouvel automate.
La seule façon d’atteindre l’état final à partir de l’état de départ consiste à suivre un arc étiqueté e dirigé vers R1 (resp. vers R2) puis de reconnaître un mot de L(R1) (resp. de L(R2)) et à partir de l’état d’acceptation de R1 (resp. R2) d’effectuer la e-transition vers l’état d’acceptation de L(R1) È L(R2) c’est-à-dire L(R).
2) R = R1 . R2

L’état final de R1 et l’état initial de R2 deviennent des états ordinaires. L’état initial de R1 devient l’état initial de R et l’état final de R2 devient l’état final de R.
La seule façon de passer de l’état à l’état final est de lire un mot de R1 puis de lire un mot de R2.
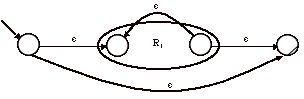 3) R
= R1* = e + R1+
3) R
= R1* = e + R1+
La répétition non nulle (+) consiste à relier l’état final de l’automate de R à son état initial. Pour ajouter e au langage reconnu par l’automate, il suffit de créer un nouvel état initial et un nouvel état final et de les relier avec une transition e.
Pour passer de l’état initial à l’état final, on passe soit par la transition directe e (et le mot e est reconnu), soit on passe par une reconnaissance du L(R1) puis une transition directe. Lorsque l’on a reconnu un mot de L(R1), il est possible de recommencer un nombre quelconque de fois en utilisant la e-transition entre l’état final et l’état initial de R1.
4 Expliquer pourquoi pour rajouter e au langage reconnu par un automate A, il n’est pas possible dans le cas général de rendre l’état initial de A final.
Donner un exemple. Exhiber un cas particulier où l’on pourrait procéder de la sorte.
3
Donc d’après 1), 2) et 3) nous avons vérifié S (n+1).
et donc S(n) est vraie pour tout n.
 > Considérons par exemple l’expression régulière : a
+ bc*
> Considérons par exemple l’expression régulière : a
+ bc*
La structure syntaxique est :
Soient pour chacun des atomes « a », « b » et « c », les automates suivants :
![]()
![]()
![]()
Automate pour c* :
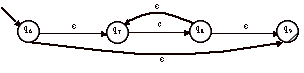
![]()
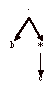 Automate pour bc* :
Automate pour bc* :
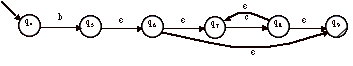
Automate pour a+ bc* :
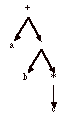
Il est possible (et même recommandé) de simplifier cet automate.
<
4 Essayer de trouver l’expression régulière à l’automate ci-dessus. Comment peut-on décomposer les chemins de l’automate ?
Réponses : On peut essayer de lire les chemins de l’automate. L’absence de boucle trop compliquée doit rendre cette lecture possible.
Nous avons les chemins suivants avec leur expression régulière associée :
<q0, q1, q2, q3> º e.a.e º a
<q0, q4, q5, q9, q3> º e.b.e.e.e º b
<q0, q4, q5, q6, q7, q8, q9, q3> º e.b.e.e.c.(e.c)*.e.e º b.cc*
L’expression régulière de l’automate est l’union des expressions régulières ci-dessus : a + b + bcc* = a + bc*
3
2.4. Élimination des e-transitions
Dans un automate, si l’on se trouve dans un état q quelconque comportant des e-transitions, on se trouve en réalité dans le même temps dans chaque état accessible q’ à partir de q en suivant les e-transitions.
En effet, soit le w le mot étiquetant le chemin de q0 (état initial) à q, alors w. e (= w) est le chemin étiquetant le chemin de q0 à q’.
L’élimination des e-transitions est effectuée en quatre étapes :
1. Augmentation des transitions ;
2. Propagation des états finals ;
3. Suppression des e-transitions ;
4. Élimination des états inaccessibles.
On construit un nouvel automate où il existe une transition entre l’état qi et l’état qj étiqueté par x s’il existe un état qk tel qu’il existe une suite d’e-transitions que qi à qk et qu’il existe une transition x de qk à qj.
> Si on augmente les transitions à partir de l’automate donné en exemple ci-dessus, on obtient le nouvel automate suivant :
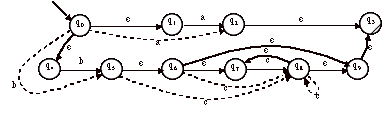
Un état est final s’il existe une suite d’e-transitions qui mène à un état final.
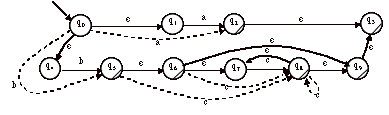
On supprime les e-transitions.
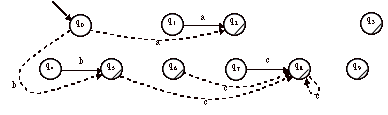
On supprime les états inaccessibles à partir de l’état initial.
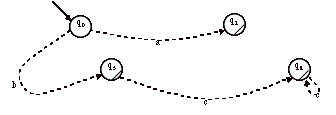
On obtient comme résultat final l’automate défini à partir de l’expression régulière = a + bc*. <
3. Transformation d’un automate en une expression régulière
3.1. Par réduction d’automates
Dans la méthode par réduction d’automates, la construction de l’expression régulière définissant le même langage que celui reconnu par l’automate passe par la suppression successive des états de l’automate A.
Pour ce faire, on remplace successivement l’étiquetage des transitions de l’automate par des expression régulières.
On considère l’étiquette d’un chemin comme la concaténation des expressions régulières associées à ce chemin.
> Par exemple :
![]()
![]()
<
Soit un automate déterministe A. Considérons un état q non-final à n états prédécesseurs (pi) et n états successeur (si) et éventuellement une transition sur lui-même. Cet état q peut-être éliminé à condition de « mettre à jour » les transitions restantes de l’automate
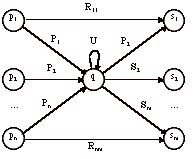
Chaque transition est définie par une expression régulière. L’élimination de q doit donc modifier les transitions pi à sj (pour tout 1£i£ n et 1£j£m).
La transition allant de pi à sj
sera modifiée de façon à porter l’expression régulière : Rij +
PiU*Sj
En effet, si on passe de pi à sj directement cela s’effectue en acceptant un mot de l’expression régulière Rij.
Si on passe par q, il faut :
Reconnaître un mot défini par Pi ;
Reconnaître 0 ou n fois un mot défini par U ;
Reconnaître un mot défini par Si.
Donc au total, il faut reconnaître un mot de l’expression régulière PiU*Sj.
 La méthode consiste donc à éliminer tous les états sauf les états
finals (et bien sûr l’état initial). Lorsque l’automate ne comprend qu’un état
initial et un état final (éventuellement confondus), on peut en déduire le
langage reconnu.
La méthode consiste donc à éliminer tous les états sauf les états
finals (et bien sûr l’état initial). Lorsque l’automate ne comprend qu’un état
initial et un état final (éventuellement confondus), on peut en déduire le
langage reconnu.
Le langage reconnu est : S*U(T + VS*U)*.
Si l’automate A ne comporte plus qu’un seul état initial et n (n>1) états finals (notés Fi), on crée n copies de l’automates. Pour chaque copie Ai, seul l’état Fi est final. L’expression régulière R(A) sera l’union des expressions R(Ai) : R(A) = R(A1) + R(A2) + R(A3) + … R(An)
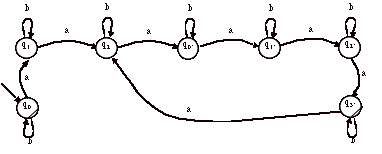
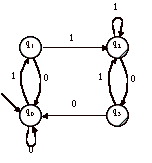 > Soit par exemple, l’automate A suivant :
> Soit par exemple, l’automate A suivant :
Essayons de trouver une expression régulière R(A) du langage L(A).
On souhaite éliminer l’état q1. Les prédécesseurs de q1 sont {q0}. Les successeurs de q1 sont {q0, q2}. Il n’y aucune boucle sur q1, on considère donc qu’il y a une boucle étiquetée f.
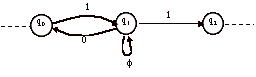
On supprime q1 et on ajoute les transitions q0-q0 et q0-q2.
On obtient donc l’automate A’ suivant :
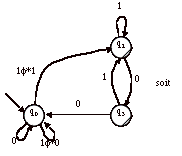
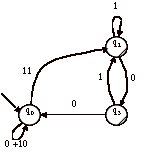
L’automate A’ contient deux états finals et un état initial. Il n’est pas possible continuer à éliminer directement des états, il est nécessaire de dupliquer A’.
Soient B et C, les deux copies de A’ :
et
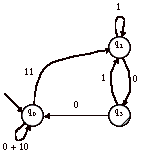
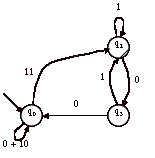
 Pour B, on élimine q3 :
Pour B, on élimine q3 :
Le langage reconnu par B est : (0+10)*11(1+01+00(0+10)*11)*
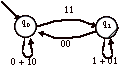
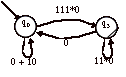 Pour C, on élimine q2 :
Pour C, on élimine q2 :
Le langage reconnu par C est : (0+10)*111*0(1*10+0(0+10)*111*0)*
Le langage reconnu par A est donc :
(0+10)*11(1+01+00(0+10)*11)*
+ (0+10)*111*0(1*10+0(0+10)*111*0)*
<
4 : essayer de monter que l’expression régulière R(A) ci-dessus décrit le langage L sur {0, 1} de tous les mots possibles ne se finissant pas par « 00 ».
Éléments de réponse :
Une expression régulière simple pour L est : (0+1)*01 + (0+1)*10 + (0+1)*11
On peut observer l’expression régulière R(A).
Avons-nous R(A) = R(L) ? Il y a plusieurs manières de procéder. Lesquelles ?
3
3.2. Par résolution d’équations
À partir d’un automate A, il est possible de poser les équations décrivant les langages reconnus par chaque état. C’est-à-dire que pour chaque état on se pose la question suivante « quel serait le langage reconnu en commençant par cet état ? ».
Pour n états, on trouvera donc, n équation à n inconnues. On note L(i), le langage reconnu à partir de l’état i. L’objectif est de résoudre l’équation pour la variable L(0). L(0) est le langage reconnu à partir de l’état initial, c’est-à-dire le langage reconnu par l’ensemble de l’automate donc L(A).
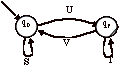 Comme pour la méthode par réduction d’automates, le cas général minimal
est :
Comme pour la méthode par réduction d’automates, le cas général minimal
est :
Les équations associées sont :
L(0) = S . L(0) + U . L(f)
L(f) = T . L(f) + V . L(0) + e
On remarquera qu’un état final reconnaît au moins {e}, c’est-à-dire l’expression régulière e.
La résolution du système d’équation se fait comme en arithmétique par substitution et réécriture. De plus, quand on trouve une équation de la forme : L = xL + y alors sa solution est x*y.
L = xL + y Þ L = x*y
Résolvons le système d’équations ci-dessus :
a) L(0) = S . L(0) + U . L(f)
b) L(f) = T . L(f) + V . L(0) + e
on obtient par résolution
c) L(f) = T*(V . L(0) + e)
on remplaçant L(j) dans a)
d) L(0) = S . L(0) + UT*(V . L(0) + e)
L(0) = (S + UT*V) L(i) + UT*
L(0) = (S + UT*V)*UT*
Nous avons L(0) = S*(UT*VS*)*UT*
car (x + y)* = x*(yx*)* et ici x = S et y = UT*V
L(0) = S*U(T*VS*U)*T*
car (xy)*x = x(yx)* et ici x = U et y= T*VS*
L(0) = S*U(VS*U + T)*
car (x*y)*x* = (x + y)*et ici x = T et y = VS*U
L(0) = S*U(T + VS*U)*
Donc nous avons : (S + UT*V)*UT* = S*U(T + VS*U)*. C’est-à-dire que dans le cas général minimal on obtient un résultat équivalent à celui par la méthode de réduction d’automate.
4 démontrez que la méthode par résolution d’équation est équivalente à celle de réduction d’automates.
Éléments de réponse : il est possible de procéder par induction. La suppression d’un état équivaut à la substitution de la variable associée dans le système d’équations. Quel est le cas de base ?
3
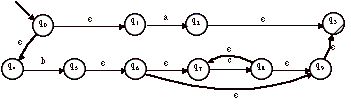
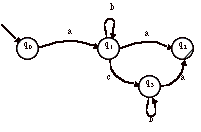
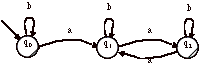
> Par exemple, soit l’automate A suivant :
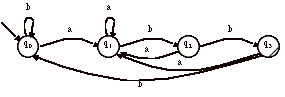
Cet automate est l’automate déterministe reconnaissant les mots de la forme :(a+ b)*abb. Essayons de retrouver l’expression régulière.
On pose les équations suivantes :
a) L(0) = bL(0) + aL(1)
b) L(1) = aL(1) + bL(2)
c) L(2) = aL(1) + bL(3)
d) L(3) = bL(0) + aL(1) + e
On peut dans c) remplacer L(3) par sa définition
e) L(2) = aL(1) + b(bL(0) + aL(1) + e)
L(2) = aL(1) + bbL(0) + baL(1) + b
On peut dans b) remplacer L(2) par sa définition
f) L(1) = aL(1) + b(aL(1) + bbL(0) + baL(1) + b)
L(1) = aL(1) + baL(1) + bbbL(0) + bbaL(1) + bb
L(1) = (a + ba + bba)L(1) + bbbL(0) + bb
L(1) = (a + ba + bba)*(bbbL(0) + bb)
On peut remplacer dans a) remplacer L(1)
g) L(0) = bL(0) + a(a + ba + bba)*(bbbL(0) + bb)
L(0) = bL(0) + a(a + ba + bba)*bbbL(0) + a(a + ba + bba)*bb
L(0) = (b + a(a + ba + bba)*bbb)L(0) + a(a + ba + bba)*bb
L(0)= (b + a(a + ba + bba)*bbb)*a(a + ba + bba)*bb
Cette expression régulière semble difficile à simplifier, toutefois essayons de démontrer qu’elle est bien égale à (a + b)*abb.
Supposons donc :
(a + b)*abb = (b + a(a + ba + bba)*bbb)*a(a + ba + bba)*bb
si on supprime « bb » de part et d’autre, on a l’égalité :
Þ (a + b)*a = (b + a(a + ba + bba)*bbb)*a(a + ba + bba)*
Þ (a + b)*a = (b + a((e + b + bb)a)*bbb)*a((e + b + bb)a)*
Þ (a + b)*a = (b + (a(e + b + bb))*abbb)*(a(e + b + bb))*a
car x(yx)* = (xy)*x
si on supprime « a » de part et d’autre, on a l’égalité :
Þ (a + b)* = (b + (a(e + b + bb))*abbb)*(a(e + b + bb))*
Þ (a + b)* = (b + (a + ab + abb)*abbb)*(a + ab + abb)*
Þ (a + b)* = b*((a + ab + abb)*abbbb*)*(a + ab + abb)*
car (x + y)* = x*(yx*)*
Þ (a + b)* = b*((a + ab + abb) + abbbb*)*
car (x*y)*x* = (x + y)*
Þ (a + b)* = b*(a + ab + abb + abbbb*)*
Þ (a + b)* = b*(a (e + b + bb + bbbb*))*
Þ (a + b)* = b*(a b*)*
ce qui est vrai car (x + y)* = x*(yx*)*
Donc on a bien :
(a + b)*abb = (b + a(a + ba + bba)*bbb)*a(a + ba + bba)*bb
Donc l’automate reconnaît bien le langage (a + b)*abb
<
4 Dans l’exemple précédent, nous avons supposé que :
X* = (e + X + XX + XXXX*)
Pouvez-vous le démontrer ?
Pouvez-vous démonter le cas général : X* = (e + X + XX + XXX + … + XnX*)
Réponses :
X* = (e + X + XX + XXX(e + X + XX + …))
(e + X + XX + XXX + XXXX + XXXXX + …)
X*
X* = (e + X + XX + XXX + … + XnX*)
(e + X + XX + XXX + … + Xn(e + X + XX + …))
(e + X + XX + XXX + … + Xn + XnX + XnXX + …)
(e + X + XX + XXX + … + Xn + Xn+1 + Xn+2 + …)
X*
On remarquera que X* = (X*)n = (X*)*
3
4 Dans l’exemple précédent, plusieurs fois, on a supprimé un mot de part et d’autre d’une égalité afin de la démontrer. Dans quel cas ne peut-on pas le faire et pourquoi ?
Vérifier que (a + b)*ab(a +b)* = b*a*ab(a+b)*
Avons-nous (a + b)*ab = b*a*ab ? Expliquez.
3
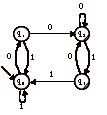 4 Soit l’automate A suivant :
4 Soit l’automate A suivant :
Produisez l’expression régulière de A à l’aide de la méthode de résolution d’équations. Quel langage reconnaît cet automate ?
Réponse (non détaillée) : il s’agit de tous les mots sur {0, 1} sauf 11.
3
4. Déterminisation & Minimisation
4.1. Méthode de déterminisation
Si dans un automate A, il existe deux chemins q0…qn et q0…qm décrivant le même mot alors ces deux chemins appartiennent à la même classe d’équivalence. Ils peuvent donc être regroupés en un seul chemin pour ce mot. Cette constatation est à la base de la méthode déterminisation.
Propriété :
Pour tout automate d’états finis non-déterministe, il existe un automate d’état fini déterministe équivalent.
Soit A = (VT, Q, Q0, F, m) un AEF non-déterministe
Alors A’ = (VT, P(Q), Q0, F’, m’)
![]()
avec F’ =
{Q’’ | Q’’ Ç F ≠ Æ}
Alors L(A) = L(A’)
4 Démonstration de la propriété ci-dessus
3
La méthode consiste à définir des transitions sur des ensembles d’états et non des états. À partir d’un ensemble d’états, on définit l’ensemble successeur pour un x de V comme l’ensemble des états atteignables par x depuis un état de l’ensemble. Seule une partie des sous-ensembles possibles est utile. Pour calculer les sous-ensembles utiles, on itère jusqu’à ce que aucun nouveau sous-ensemble soit créé. L’ensemble de départ est l’ensemble des états initiaux. Chaque ensemble d’états correspond à un état de l’automate déterministe. Un état est final si un des états d’origine le composant est final.
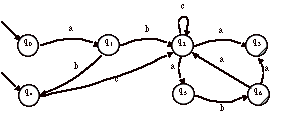 > Soit par exemple, A l’automate non-déterministe suivant :
> Soit par exemple, A l’automate non-déterministe suivant :
Nous obtenons la table de transitions suivantes :
|
|
|
a |
b |
c |
|
® 0 |
{0, 4} |
{1} |
- |
{2} |
|
1 |
{1} |
- |
{2, 4} |
- |
|
2 |
{2} |
{3, 5} |
|
{2} |
|
3 |
{2, 4} |
{3, 5} |
- |
{2} |
|
¬ 4 |
{3, 5} |
- |
{6} |
- |
|
¬ 5 |
{6} |
{2, 3} |
- |
|
|
¬ 6 |
{2, 3} |
{3, 5} |
- |
{2} |
<
4 Créer la table de transitions de l’automate non-déterministe. Dessiner et commentez l’automate déterministe ci-dessus.
3
4.3. Relation d’équivalence sur les langages réguliers
À partir de la notion d’automate, on peut définir une relation d’équivalence sur les mots de VT*.
Si deux mots distincts conduisent dans un automate A à l’état qi, alors ces deux mots sont équivalents.
Définition : w1 » w2 Û " z Î VT*, w1z Î L Û w2z Î L
La relation » est réflexive w1 » w1
La relation » est symétrique w1 » w2 Þ w2 » w1
La relation » est transitive w1 » w2, w2 » w3 Þ w1 » w3
Soit un automate A reconnaissant le langage L.
Relation réflexive :
w Î L(A) Û (q0, w) a* (q, e) q Î F
Par définition de a* (q0, w1) a* (q, e) Þ (q0, w2) a* (q, e)
donc w1 » w1
Relation symétrique :
w1 » w2 :
" z Î VT* (q0, w1z) a* (q,, e) q Î F
Û (q0, w2z) a* (q’, e) q’ Î F
donc " z Î VT* (q0, w2z) a* (q’, e) q’ Î F
Û (q0, w1z) a* (q,, e) q Î F
donc w2 » w1
Relation transitive :
w1 » w2 et w2 » w3 :
w1 » w2 : " z Î VT* (q0, w1z) a* (q,, e) q Î F
Û (q0, w2z) a* (q’, e) q’ Î F
w2 » w3 : " z Î VT* (q0, w2z) a* (q,, e) q Î F
Û (q0, w3z) a* (q’, e) q’ Î F
" z Î VT* (q0, w1z) a* (q, e) q Î F
Û (q0, w2z) a* (q’ e) q’ Î F
Û (q0, w3z) a* (q’’ e) q’’ Î F
> Soit, par exemple, l’automate suivant :
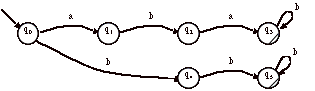
Les états q2 et q4 sont »
Soient les mots ab et b, ils sont »
En effet, pour q2 : (q0, ab) a (q2, e)
Ensuite un mot appartient à L si et seulement si, il est de la forme ab*
pour q4 : (q0, b) a (q4, e)
Ensuite un mot appartient à L si et seulement si, il est de la forme ab*
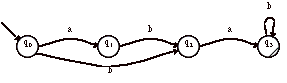 Nous aurions pu définir l’automate :
Nous aurions pu définir l’automate :
La relation d’équivalence nous permet de définir un automate ayant un nombre minimum d’états.
ici on n’a pas e » a car e.aba Î L
a.aba Ï L
Donc q0 et q1 n’appartiennent pas à la même classe d’équivalence. <
Une relation d’équivalence est invariante à droite si et seulement si :
" w1,w2 Î VT* w1 » w2 Þ " z Î VT* w1z » w2z
Les propriétés suivantes sont équivalentes :
a) le langage L est reconnu par un automate d’états fini ;
b) le langage L est la réunion d’un ensemble de classes d’équivalence d’une relation d’équivalence invariante à droite d’index fini.
Démonstration :
1) a Þ b
Soit A un automate d’états fini tel que L = L(A).
Alors soit R la relation :
w1 Â w2 Û (q0,
w1) a* (q, e) Ù
(q0, w2) a* (q, e)
 est un relation d’équivalence réflexive, symétrique et transitive.
Soit [q] la classe d’équivalence définie par :
w Î [q] Û (q0,
w) a* (q, e)
![]()
Alors
 est d’indice fini.
2) b Þ a
Soit  la relation d’équivalence. On défini donc un automate d’état fini tel que :
Q = {[w] | w Î VT*} l’ensemble des classes
Q est fini car l’indice de la relation est fini.
A = (VT, Q, [e], F, m)
F = {[w] | w Î L]
m : m([w], s) = [ws]
donc " z Î VT* ([e], w) a* ([w], e)
et w Î L Û [w] Ì L
4 soit L le langage sur {a, b} dont les mots contiennent au moins un « ab ». Donnez une expression régulière simple de ce langage. Construisez les automates non-déterministe et déterministe.
Quels états de l’automate déterministe peut-on regrouper dans de mêmes classes d’équivalence ?
Réponses : (peu détaillée)
R(L) = (a + b)*ab(a + b)*
On a comme automates A et Adet :
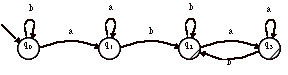
Pour avoir si deux état de Adet sont équivalents, posons et résolvons les équations d’états pour Adet :
L0 = bL0
+ aL1
L1 = aL1 + bL2
L2 = bL2 + aL3 + e
L3 = bL2 + aL3 + e
On constate que L2 = L3. Ici, on n’a pas besoin de résoudre l’équation pour constater que les deux langages sont égaux, car les parties droites des équations sont identiques. Toutefois on gardera à l’esprit, que si deux équations sont différentes, il est possible que leurs solutions soient égales.
Si on résout L3
L3 = a*(bL2 + e)
Donc
L2 = bL2 + aa*(bL2 + e) + e
L2 = (b + aa*b)L2 + aa* + e
L2 = (b + aa*b)*(aa* + e)
Donc
L2 = (b + aa*b)*a* = (( e + aa*)b)*a* = (a*b)*a* = (a + b)*
On obtient bien la même chose pour L3.
On peut donc simplifier l’automate Adet en Adet’ :
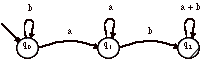
Vérifiez si l’automate peut être simplifié plus avant.
3
4 soit L’ le langage décrit par l’expression régulière b*a*ab(a+b)*.
Montrer que L’ est équivalent au langage L de l’exercice précédent.
Commentez.
3
5. Autres opérations sur les automates
5.1. Automate complémentaire ¬A
Il peut être difficile de trouver à partir de l’expression régulière le complémentaire ¬L d’un langage régulier L. Par contre, produire le complémentaire ¬A d’un automate régulier déterministe A est aisé.
Pour produire à partir de A (qui reconnaît le langage L(A)) l’automate complémentaire ¬A reconnaissant le langage complémentaire ¬(L(A)), il suffit de :
Créer un état trappe T ;
Soit vi les éléments du vocabulaire V sur lequel est défini L(A). Pour chaque état q, créer une transition vi de q vers T s’il n’existe pas de transition vi partant de q ;
Chaque état final devient ordinaire et chaque état ordinaire devient final. L’état initial reste initial. L’état trappe T devient final.
Si l’état trappe T n’est pas relié, il pourra être supprimé.
> Soit, par exemple, L le langage sur V = {a, b, c} composé de mots composé que de a ou de b et contenant une fois une séquence de 0 ou n « c ». Essayons de produire l’expression régulière de ¬L.
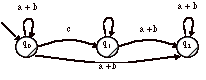 L’expression régulière R(L) est (a + b)*c*(a + b)* et l’automate
non-déterministe est :
L’expression régulière R(L) est (a + b)*c*(a + b)* et l’automate
non-déterministe est :
c
L’automate déterministe équivalent est :
|
|
|
a |
b |
c |
|
® ¬ 0 |
{0} |
{0, 2} |
{0, 2} |
{1} |
|
¬ 1 |
{0, 2} |
{0, 2} |
{0, 2} |
{1} |
|
¬ 2 |
{1} |
{2} |
{2} |
{1} |
|
¬ 3 |
{2} |
{2} |
{2} |
- |
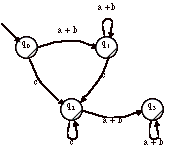
On créé un état trappe T et on sature les transitions de l’automate vers cet état. Le langage est inchangé.
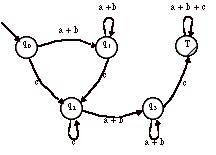 On inverse les états finals et non-finals. L’automate obtenu reconnaît
¬L.
On inverse les états finals et non-finals. L’automate obtenu reconnaît
¬L.
L’expression régulière peut être trouvée par la méthode des équations d’états. L’automate est saturé, chaque équation comportera trois termes (pour a, b et c) pour un état ordinaire et on rajoutera e pour les états finals.
a) L0 = (a + b)L1 + cL2
b) L1 = (a + b)L1 + cL2
c) L2 = (a + b)L3 + cL2
d) L3 = (a + b)L3 + cLT
e) LT = (a + b + c)LT + e
LT = (a + b + c)* = V*
L3 =
(a + b)*cLT
= (a + b)*c(a + b +
c)*
L2 =
c*(a + b)L3
= c*(a + b)(a +
b)*c(a + b + c)*
L1 =
(a + b)*c L2
= (a + b)*cc*(a + b)(a + b)*c(a + b + c)*
L0 =
L1
= (a + b)*cc*(a + b)(a + b)*c(a + b + c)*
Il s’agit du langage des mots quelconques sur {a, b} qui comportent au moins 2 séquences non nulles de c.
Il s’agit bien du complémentaire du langage qui comporte une seule séquence éventuellement nulle de c.
D’après les équations ci-dessus, on s’aperçoit que q0 et q1 sont dans la même classe d’équivalence. On peut donc simplifier l’automate :
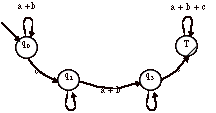
<
4 Décrire et caractériser la classe des automates réguliers invariants par l’opération de complémentation. Commentez.
3
4 L’opération de complémentation fonctionne-t-elle sur des automates non-déterministe ? Commentez.
3
5.2. Automate miroir A~
Pour produire à partir de A (qui reconnaît le langage L(A)) l’automate miroir A~ reconnaissant le langage miroir (L(A))~, il suffit de :
Inverser le sens des transitions ;
Échanger les états initiaux et les états finals ;
Déterminiser l’automate produit (si nécessaire).
On notera que L(A~) = L(A)~. Il s’agit juste d’un jeu d’écritures.
L’opération consistant à inverser le sens des transitions, peut à partir d’un automate déterministe produire un automate non-déterministe.
>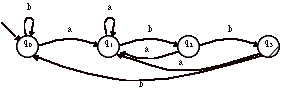 Par exemple, soit
l’automate A suivant :
Par exemple, soit
l’automate A suivant :
Cet automate est l’automate déterministe reconnaissant les mots de la forme :(a + b)*abb
Après inversion des transitions et des états, nous avons l’automate miroir non-déterministe (A~)ndet suivant :
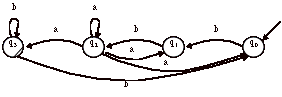
L’automate déterministe A~ équivalent est :
|
|
|
a |
b |
|
® 0 |
{0} |
- |
{1} |
|
1 |
{1} |
- |
{2} |
|
|
{2} |
{0, 1, 2, 3} |
- |
|
¬ 3 |
{0, 1, 2, 3} |
{0, 1, 2, 3} |
{0, 1, 2, 3} |
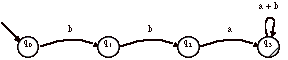
Cet automate est déterministe et reconnaît les mots de la forme bba(a + b)* = ((a + b)*abb)~
 On remarquera que si on cherche à produire l’image miroir de l’automate
ci-dessus, c’est-à-dire (A~)~, on obtiendra avant déterminisation l’automate
non-déterministe du langage (a + b)*abb. <
On remarquera que si on cherche à produire l’image miroir de l’automate
ci-dessus, c’est-à-dire (A~)~, on obtiendra avant déterminisation l’automate
non-déterministe du langage (a + b)*abb. <
|
4 soit l’automate A ci-contre : Trouver l’expression régulière du langage reconnu par A. Construire l’automate A~ et trouver l’expression du langage reconnu. Commentez. |
|
Réponses L’expression régulière correspondante est R(A) = ab*a + ab*cb*a = ab*(a + cb*a). Si on inverse le sens des flèches et que les états initiaux deviennent finals et que les états finals deviennent initiaux alors on obtient :
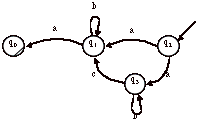
L’automate non-déterministe miroir A~ est (après avoir renommé les états) :
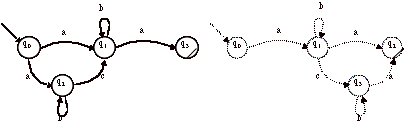
L’expression régulière R(A~) est : ab*a + ab*cb*a
On remarque ici que R(A~) = R(A), donc L(A~) = L(A), donc L(A) = L(A)~. Le langage L(A) est donc un langage dont l’expression régulière est une union de palindromes. Ceci ne veut pas dire que les mots de L(A) sont nécessairement des palindromes.
La version déterministe de cet automate est :
|
|
|
a |
b |
c |
|
® 0 |
{0} |
{1, 2} |
- |
- |
|
1 |
{1, 2} |
{3} |
{1, 2} |
{1} |
|
|
{1} |
{3} |
{1} |
- |
|
¬ 3 |
{3} |
- |
- |
- |
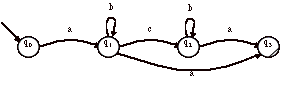
Il s’agit du même automate que A.
3
4 Est-il possible d’obtenir un automate déterministe à partir d’un automate non-déterministe après inversion des transitions ? Et à partir d’un automate déterministe ?
3
4 Décrire et caractériser la classe des automates réguliers invariants par l’opération miroir.
3
5.3. Intersection de deux automates
La production de l’expression régulière du langage L = L1 Ç L2 à partir des expressions régulière de L1 et L2 n’est pas aisée. Par contre, il existe une méthode simple pour construire l’intersection de deux automates déterministes A1 et A2.
Un mot appartient à deux automates déterministes A1 et A2 si on est capable de suivre dans les deux automates un chemin décrivant ce mot de l’état initial à un état final.
A1= (VT1, Q1, Q01, F1, m1) et A2= (VT2, Q2, Q02, F2, m2)
w Î L(A) = L(A1 Ç A2) si et seulement si :
$ (q,q’) Î F1 ´ F2 : ((q01,q02), w) a* ((q,q’), e)
Le mot w appartient au langage reconnu par l’automate A s’il existe un chemin de l’état initial à un état final qui décrit ce mot à la fois dans A1 et A2.
La construction de A = A1 Ç A2 consiste à parcourir en parallèle les deux automates, et à ne retenir comme état que les couples d’états atteignables à la fois dans les deux automates.
Un état q du nouvel automate A sera final si les deux états (q’, q’’) issus de A1 et A2 sont finals.
> Exemple : Soit La2, le langage sur {a,b} composé de n « a », ou n est un multiple de 2. Soit La3, le langage composé d’une succession de n « a », ou n est un multiple de 3.
Quelle est l’intersection de La2 et La3 ?
R(La2) = b*(ab*ab*)* et R(La3) = b*(ab*ab*ab*)*
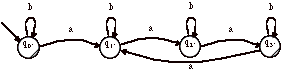
On obtient la table de transitions suivante :
|
|
|
a |
b |
|
® 0 |
(0,0’) |
(1, 1’) |
(0, 0’) |
|
1 |
(1, 1’) |
(2, 2’) |
(1, 1’) |
|
2 |
(2, 2’) |
(1, 3’) |
(2, 2’) |
|
3 |
(1, 3’) |
(2, 1’) |
(1, 3’) |
|
4 |
(2, 1’) |
(1, 2’) |
(2, 1’) |
|
5 |
(1, 2’) |
(2, 3’) |
(1, 2’) |
|
¬ 6 |
(2, 3’) |
(1, 1’) |
(2, 3’) |
R(A) = b*(ab*ab*ab*ab*ab*ab*)*
Il s’agit du langage La6.
<
4 D’une façon générale, que peut-on dire de Lan Ç Lam (n³1 et m³1) ?
Calculez également La2 Ç Lb2 et généralisez vos résultats.
Réponses : A(La2 Ç Lb2) à 9 états et reconnaît les mots ou le nombre de a et le nombre de b sont pairs.
Un automate Lan a n+1 états. A(Lan Ç Lbm) à (m + 1)*(n + 1) états.
La définition fonctionnelle de A(La2 Ç Lb2) est :
V= {a, b} F = {6, 7, 8} Q0 = {0} Q = {0, 1, 2, 3, 4 5, 6, 7 ,8}
d(0,a) = 1 d(0,b) = 2 d(1,a) = 3 d(1,b) = 5
d(2,a) = 5 d(2,b) = 4 d(3,a) = 1 d(3,b) = 7
d(4,a) = 6 d(4,b) = 2 d(5,a) = 7 d(5,b) = 6
d(6,a) = 8 d(6,b) = 5 d(7,a) = 5 d(7,b) = 8
d(8,a) = 6 d(8,b) = 7
3
4 On appelle A(f), la classe d’automates n’acceptant aucun mot. Quelle est la propriété suffisante pour qu’un automate appartienne à A(f). Quelle propriété doivent vérifier les automates pour qu’elle soit aussi nécessaire ?
Montrer que cette classe d’automates réguliers est infinie.
Montrer que quelque soit A, on a : A Ç ¬A Î A(f).
3
6. Conclusion
Nous avons introduit dans ce chapitre le concept d’automate à état finis régulier. Ce type de machine abstraite est équivalent aux langages réguliers et aux expressions régulières. Cependant, un certain nombre d’opérations de manipulation se font aisément sur les automates, ce qui n’est pas nécessairement le cas sur les expressions régulières.