
David NOVO's homepage
CNRS Research Scientist (HDR)

About Me
I am a CNRS Research Director (equivalent to Full Professor) in the ADAC Group at LIRMM, Montpellier, France, since January 2017. The LIRMM is a joint research unit owned by the French National Center for Scientific Research (CNRS) and the University of Montpellier (UM).
Previously, I was a post-doctoral researcher at the EPFL School of Computer and Communication Sciences, Switzerland, where I joined the Processor Architecture Laboratory (LAP) in November 2010. Even longer ago, I conducted my doctoral research at the Interuniversity Microelectronics Centre (imec), Belgium, receiving the Ph.D. in Engineering from the Katholieke Universiteit Leuven (KU Leuven) in 2010.
My research interests include hardware and software techniques for increasing computational efficiency in next-generation digital computers, with particular focus on memory systems for multi-core architectures and programmable accelerators for machine learning applications.
You can find here a list of my publications.

Do You Want to Work with Me?
We are always looking for enthusiastic and motivated students and researchers to join our group. If you are a student with a strong interest in my areas of research, do not hesitate to contact me for possible Master Thesis, internships, and Ph.D. positions. You can also contact me if you are looking for a postdoc position and you have ideas for applying for your own funding. I am happy to support such applications.
My Research Vision
I am interested in pushing computation efficiency beyond the end of CMOS scaling. So far, the relentless scaling of CMOS technology has been the major factor behind the unprecedented increase in computational efficiency of the last decades. In essence, transistor density doubled every two years (aka Moore’s law). However, CMOS scaling is currently approaching fundamental limitations, and we are in desperate need of new paradigms to keep on pushing the limits of computational efficiency. I believe that plenty of optimization potential hides in the design abstractions developed throughout Moore’s law era.
The figure shows the traditional computational abstractions bridging the application on the top with the laws of physics on the bottom. Over the years, large research communities have grown in each of these abstraction layers. Each community has thrived within the comfort of its abstraction walls (e.g., for an architect, a memory is just characterized by symmetric access latencies, symmetric access energies, unlimited endurance, and unlimited retention time). However, the time has come to roll up our sleeves and question the inherited abstraction interfaces so that we can fully embrace emerging device technology, such as new non-volatile memory technologies.
In my research, I am contributing to this effort of revisiting computational abstractions from two different fronts depending on the purpose of the targeted computation. Accordingly, I differentiate between general-purpose computing and domain-specific computing. Domain-specific computing covers a narrow functionality within a particular application domain (deep learning in my case). Thus, domain-specific computing is more amenable to a complete vertical integration able to optimize across all design abstractions layers. Instead, general-purpose computing has become so convoluted that such a complete refactorization would seem unrealistic. Therefore, my approach here is to focus on the data storage and movement part, which is known to be the primary source of energy consumption in high-performance computing. By reducing the focus to the memory system architecture, we can then afford to explore optimization opportunities across neighboring abstractions (e.g., run-time, architecture, and device).
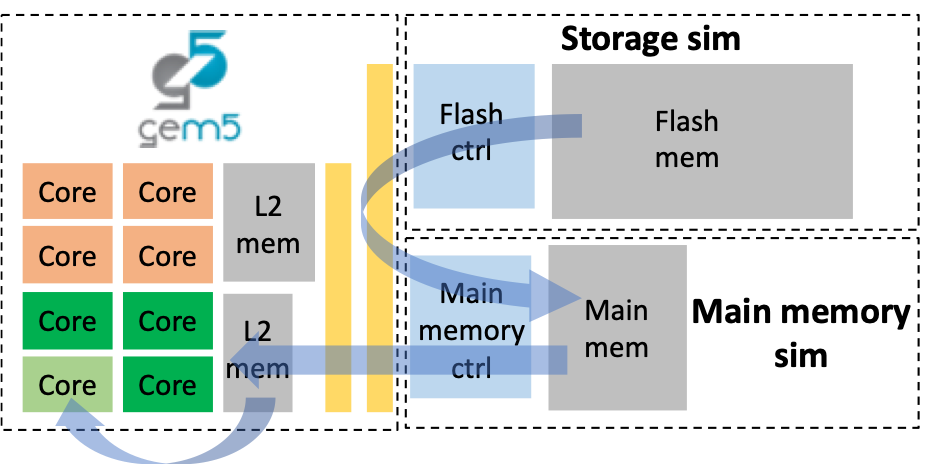
Data Movement and Storage in Multi-Core Systems On-Chip
This work targets a drastic reduction in energy waste by fundamentally rethinking data storage and movement, from memory technology up to the Operating System. In this context, we have established a strategic partnership with imec, an R&D center and innovation hub of excellence in nanoelectronics technologies. Together, we work towards enabling radically new system memory architectures, which combine traditional memory technologies with different flavors of emerging non-volatile memory (NVM) technologies (i.e., SST-, SOT-MRAM and IGZO DRAM) to achieve unprecedented levels of storage density and energy efficiency.
Traditional memory technologies, such as DRAM and SRAM, suffer from fundamental limitations that have become extremely disruptive with technology scaling. Conveniently, some emerging NVM technologies are shown to be more scalable and have near-zero leakage power, properties that can be leveraged to fit more data on-chip and achieve unprecedented levels of energy efficiency and performance. In particular, magnetic memories offer these advantages, though they are not as dense as resistive or charge-based NV memories. Thus, magnetic memories would not be usable as stand-alone memories and will need to be combined with other types of NVM memories in the layers further away from the processor cores.
However, all these emerging NVM technologies also bring new challenges that we are addressing holistically by combining techniques at the circuit, architecture, and run-time level. Such challenges include higher latencies, asymmetric read/write operations, relatively high dynamic write power, need for new access protocols, or the problems that permanent on-chip storage can bring for security. As a result, we are replacing today’s typical cache-based memory systems by hybrid memory systems augmented with smart controllers able to combine software-controlled memories and caches made from a heterogeneous mixture of different memory technologies.
PhD Students working on this topic:
- Soraya Mobaraki (funded by the ANR F3CAS project)
- Luis Bertran-Alvarez (in collaboration with ATOS/EVIDEN and funded by an ANRT CIFRE grant)
- Enzo Rafinesque (funded by imec)
PhD Thesis on this topic:
- Quentin Huppert, PhD Thesis, 2022
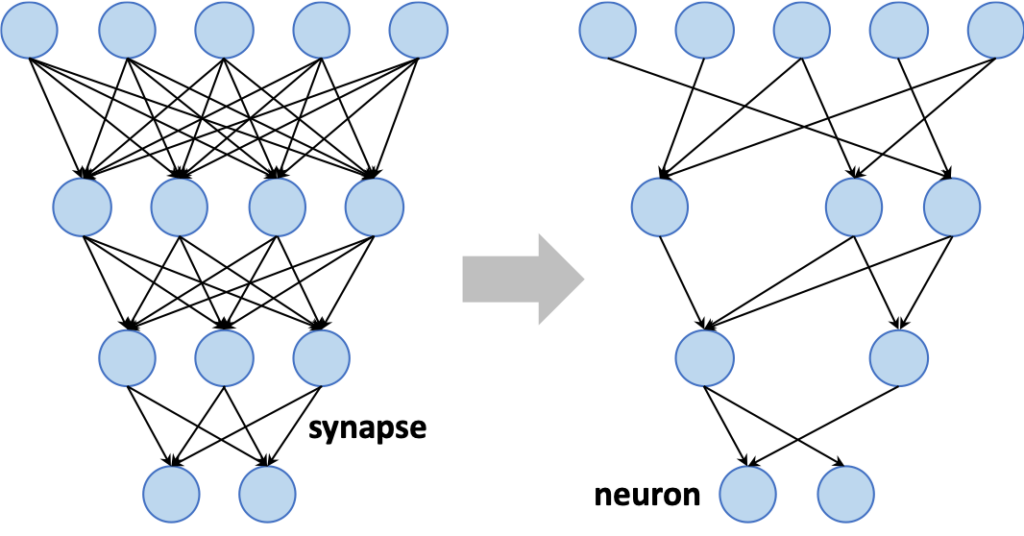
Deep Learning as Domain-Specific Computing
Deep Learning (DL) is a subfield of Machine Learning (ML) that, inspired by the functionality of our brain cells, proposes the concept of artificial Deep Neural Networks (DNNs). DL algorithms are consistently improving recognition accuracy, sometimes even exceeding human-level performance. However, these improvements are invariably tight to prohibitive computational and storage requirements, which prevents the adoption of advanced DL technology in energy constrained systems. In this work, we seek to reduce DL implementation costs by proposing new holistic design approaches to achieve high energy-efficient programmable DL inference accelerators.
The Matrix Multiplication (MM) is the fundamental operation in DL algorithms and thus, a highly efficient MM engine should be the basis for any energy-efficient accelerator. However, there is no consensus on how to build such an MM engine and two approaches coexist: (1) the traditional digital one based on multiply-accumulate operators, and (2) a more disruptive approach based on analog non-volatile memory crossbars.
But having access to an efficient MM engine is merely the first brick. The size of existing DL algorithms makes parallel implementations completely impractical, and thus the dataflow mapping choice also becomes essential. An efficient dataflow mapping can considerably reduce the cost of on-chip and off-chip memory. For instance, it can reduce the on-chip memory footprint by shortening the lifetime of intermediate data.
Furthermore, DL algorithms are inherently robust to small errors due to the generalization nature of their learning process. For instance, DL algorithms show minimal degradation when reducing the bit-width from 32 to 8 bits or when pruning more than 90% of their constants. However, to better exploit these opportunities we need to adapt the dataflow mapping and the architecture to the DL algorithm which has been now modified with approximate transformations. For instance, the mentioned weight pruning leads to a sparse MM whose best dataflow mapping and architecture are entirely different from those of a dense MM.
PhD Students working on this topic:
- Bruno Lovison-Franco (funded by the PEPR Electronique)
- Aymen Romdhane (funded by the PEPR Electronique)
- Mohammadali Zoroufchian (funded by imec)
PhD Thesis on this topic:
- Paul Delestrac, PhD Thesis, 2024
- Theo Soriano, PhD Thesis, 2022
- Etienne Dupuis, PhD Thesis, 2022
Running Funded Projects
- PEPR Electronique (member), 2023-2027
- ANR JCJC F3CAS (PI), 2021-2025
Past Funded Projects
- ANR ACHI-SEC (member), 2019-2023
- ANR NV-APROC (member), 2019-2023
- ANR AdequateDL (local PI), 2019-2023
Main Collaborations
- imec (Belgium)
- Universidad Complutense Madrid, Architecture and Technology of Computing Systems Group (Spain)
- ETH Zurich, SAFARI Group (Switzerland)
- ATOS/EVIDEN (France)