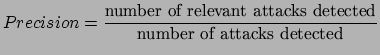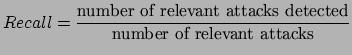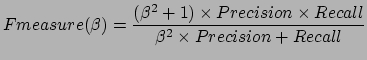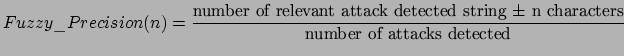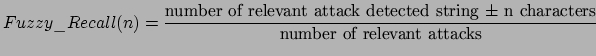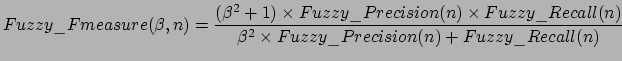Analyzing Web Traffic
ECML/PKDD 2007 Discovery Challenge
September 17-21, 2007, Warsaw, Poland




|
|
Analyzing Web Traffic
|
|
| Motivations and Tasks - Committee and Calendar - Registration - Data |
|
The OSI model is usually represented by a diagram showing a column
composed of stacked rectangular shapes, each one symbolizing a
layer of the model. However, in reality the seventh layer is much
wider and more diverse than the layers below it. This application
layer is definitely the biggest, widest, and most complex of all.
It contains more than just protocols and parameters, and is made
up of languages, scripts, libraries and human concepts...
As a consequence, the OSI model observed from a security perspective
makes the diagram take on a reversed pyramid shape. So the higher the
layers, the richer and more diverse is their content, which means they
are also more complex to secure.
![\includegraphics[width=8cm]{image.eps}](Images/img1.jpg)
Trying to filter application traffic as diverse and dynamic as Web traffic can quickly bring awareness of the existence of several strong constraints and the necessity to fulfil specific requirements.
The issue being addressed by this challenge is the filtering of
application attacks in Web traffic. This is a complex matter
because of diversity in attack purposes and means, the quantity of
data involved and technological shifts. Application attacks can be
multi-class and undergo constant change. They do however maintain
some distinguishing features (escaping, bypassing, keywords
matching external entities, etc.).
To achieve this aim data sources available from HTTP query logs
will be used. Using this data we can not only recognize an attack
but also define which class it belongs to. Participants would have
to start with an HTTP query in context and deduce which class it
belongs to and what is its level of relevance.
To address this issue in the most efficient way, we will divide
the challenge into several tasks:
The dataset will be composed of 50000 samples including 20% of
attacks. 10% of these attacks will be out of context. These
samples look like real attacks but have no chance to succeed
because they are constructed blindly and do not target the correct
entities. One sample can eventually target several classes (SQL
injection, Command execution etc. ) Each example is totally
independent of the others.
The data set will be defined in XML (portable and standard
format). Each sample will be identified by a unique id, and will
contain three major parts: Context (describes the
environment in which the query is run), Class (describes
how an expert will
classify this sample) and the description of the query itself.
The "type" element indicate which class this request belongs to :
Moreover, a flag will be added explaining whether a query is
within the assigned context or not. ( element "inContext" taking two values : TRUE or FALSE )
Another element ( "attackIntervall" ) indicates where the attack is located on the query description. This element begins with the name of the element where the attack is located ( uri, query, body, header ) followed by ":". Thereafter the interval considered as an attack is specified. For headers, we also indicate the header name where the attack is located. The interval begins from the begginning of the considered header value.
Precision and recall are the basic measures used in evaluating search strategies. For the "Analyzing Web Traffic" challenge, these criteria defined by these formulae will be used.
F-measure combines recall and precision in a single efficiency measure.
For the challenge, F-measure is calculated with ![]() = 1, meaning that the same weight is given to precision and recall.
= 1, meaning that the same weight is given to precision and recall.
Speed evaluations will only be done for runs with
![]() larger than the
larger than the
![]() average (see task 2).
The run that accomplishes the fastest and best classification will be the winner of Task 1 bis.
average (see task 2).
The run that accomplishes the fastest and best classification will be the winner of Task 1 bis.
For Task 2, the evaluation measure is based on a variant of ![]() :
:
![]() .
With
.
With
![]() , a string given as an attack is correct if the relevant attack string is more or less similar to
, a string given as an attack is correct if the relevant attack string is more or less similar to ![]() characters.
In the challenge,
characters.
In the challenge, ![]() .
.
For instance, let the string "ikjllldd" be given as an attack.
If the relevant attack is "ikjlllddio", this result is correct to compute
![]() .
.
During the Challenge on HTTP attack detection, participants will have at their disposal an evaluation machine to house the contributions competing for the different tasks. There are a number of prerequisites that need to be fulfilled for the evaluation to be carried out properly. The machine would have to be either a PC or SUN with a SunOS (version 10 ou 9) or Linux ( Kernel 2.6.x).
operating system.
In order to simplify development as much as possible and allow participants to use the programming languages of their choice, different compilers and interpreters will be hosted by the machine :
NOTE : Requests to install any other language must be made to the Challenge Team at least one month before the results of the different tasks are sent off.
On-line UNIX commands such as : autoconf, make, sed, awk, gawk, flex, bison and yacc will be available on the task evaluation machine.
To process datasets in XML format several code libraries exist for the different programming languages hosted by the machine :
http://www.rudeserver.com/cgiparser/
David Robins / HTTP-Parser-0.002 search.cpan.org/ dbrobins/HTTP-Parser-0.02/
Results should be stocked by participants programs in an export file in either XML or text-only format.
Example : <1,3,1,QUERY:45-74> means that query 1 has been classed as SQL INJECTION (i.e. an attack), that the attack is situated in the right context and that it is situated between characters 45 and 74.