Mon travail de thèse concerne l'étude de problèmes algorithmiques (développement d'algorithmes optimaux ou approchés, résultats de non-approximabilité) liés à l'ordonnancement de tâches dans le cadre du parallélisme. L'utilisation du parallélisme (c'est-à-dire l'emploi de plusieurs processeurs) pour le traitement des applications de grande taille qui réclament une puissance de calcul de plus en plus importante est aujourd'hui une réalité. En effet, il n'est plus à démontrer l'intérêt du parallélisme pour le traitement des grandes applications issues de la physique nucléaire ou le traitement des séquences de nucléotides en biologie.
Dans le but de traiter le plus rapidement possible ces types d'application, les solutions techniques qui ont été développées sont des machines parallèles avec divers choix architecturaux : des architectures parallèles avec mémoire partagé (les processeurs se partagent une mémoire centrale), à mémoire distribuée (chaque processeur dispose d'une mémoire), des machines vectorielles. Ces dernières années, il existe un regain d'intérêt pour le parallélisme avec l'apparition et l'utilisation de plus en plus croissante des grappes de stations de travail comme machine parallèle.
Néanmoins, les puissances de calcul théoriques des machines parallèles ne sont, en pratique, jamais atteintes. Ceci est dû principalement aux difficultés liées à la gestion des ressources et des contraintes de fonctionnement des architectures multiprocesseurs. Parmi les difficultés que l'on rencontre, on peut citer l'étape d'extraction du parallélisme intrinsèque d'une application ou les problèmes de routage et d'ordonnancement des communications entre les différents processeurs de l'architecture.
Pour tenter de pallier la première difficulté, une phase de partitionnement est nécessaire. Elle correspond à la première étape fondamentale de la parallélisation et consiste en l'extraction du parallélisme potentiel d'une application.
L'extraction du parallélisme détermine les dépendances fonctionnelles entre les parties de l'application. Ainsi, une application parallèle peut être représentée sous forme d'un graphe orienté sans cycle (graphe de précédence) où chaque sommet du graphe représente une partie (instruction ou ensemble d'instructions) du programme et les arcs les contraintes chronologiques entre ces parties (dites aussi contraintes de précédence).
Dans le cadre des modèles idéalisés où les communications sont considérées comme instantanées (par exemple le modèle PRAM), la mesure cruciale de la complexité parallèle est la profondeur du graphe de précédence. Or il s'avère que dans la pratique, on doit tenir compte du délai de communication entre l'instant où une information est produite par un processeur, et l'instant à partir duquel cette information peut être utilisée par un autre processeur.
Jusqu'à présent, un grand nombre de travaux théoriques ont été effectués pour le cas des communications homogènes c'est-à-dire le cas où le délai de communication entre deux tâches qui s'exécutent sur deux processeurs différents est toujours le même. La plupart des travaux considèrent le cas le plus simple, où la durée des tâches et la durée des communications sont unitaires, connu comme le problème UET-UCT (Unit Execution Time Unit Communication Time).
Le modèle hiérarchique :
Le modèle étudié dans ma thèse est une extension du modèle précédent. Nous introduisons la notion de communications hiérarchiques où on distingue deux types de communications : les communications intra-modulaires, de faibles coûts, et les communications extra-modulaires, de coûts supérieurs.
La motivation de l'extension proposée vient principalement de l'utilisation des grappes de stations de travail comme machine parallèle.
L'objectif est de trouver un ordonnancement, c'est-à-dire déterminer pour chaque tâche une date de début d'exécution et le module/processeur sur lequel elle va s'exécuter, qui minimise une fonction objectif. Pour mesurer l'impact de l'introduction des communications hiérarchiques, nous utilisons la notion de performance relative associée à une heuristique ![]() . La performance relative mesure l'écart maximum entre la valeur obtenue par l'heuristique
. La performance relative mesure l'écart maximum entre la valeur obtenue par l'heuristique ![]() pour une fonction objectif donnée, et la valeur donnée par une solution optimale.
pour une fonction objectif donnée, et la valeur donnée par une solution optimale.
Principaux résultats :
Nous avons étudié dans un premier temps le cas le plus simple où la durée des tâches est d'une unité de temps, le délai de communication extra-modulaires est également d'une unité de temps tandis que la durée de la communication intra-modulaires est nulle. Nous supposons également que le nombre de modules est non borné et chaque module est constitué de deux processeurs identiques. Nous avons en entrée un graphe de précédence quelconque et l'objectif est la minimisation de la longueur de l'ordonnancement. Nous notons par ![]() ce problème.
ce problème.
Dans un premier temps, nous nous sommes attachés à prouver un résultat de non-approximabilité [2] : nous avons démontré que le problème de décider si une instance de ![]() possède un ordonnancement de longueur au plus 4 est
possède un ordonnancement de longueur au plus 4 est
![]() -complet. Nous avons également montrer que le problème de décider si une instance de
-complet. Nous avons également montrer que le problème de décider si une instance de ![]() possède un ordonnancement de longueur au plus 3 est polynomial.
possède un ordonnancement de longueur au plus 3 est polynomial.
Ce résultat implique qu'il n'existe pas d'heuristique avec une garantie de performance inférieure à ![]() sous l'hypothèse que
sous l'hypothèse que
![]() . Nous avons également étendu ce résultat dans le cas de la minimisation de la somme des temps de fins d'exécution des tâches, et nous avons montré qu'il n'existe pas d'heuristique avec une garantie de performance inférieure à
. Nous avons également étendu ce résultat dans le cas de la minimisation de la somme des temps de fins d'exécution des tâches, et nous avons montré qu'il n'existe pas d'heuristique avec une garantie de performance inférieure à ![]() [2].
[2].
Ensuite, après avoir déterminé une borne inférieure pour la performance relative du problème ![]() , nous nous sommes attachés à déterminer une borne supérieure pour celle-ci, car il n'est pas seulement intéressant de connaître la complexité d'un problème, il est souhaitable de développer des algorithmes polynômiaux pour le résoudre de manière approchée. Nous avons proposé un nouvel algorithme d'ordonnancement basé sur la relaxation des contraintes d'intégrité d'un programme linéaire en nombre entiers modélisant le problème
, nous nous sommes attachés à déterminer une borne supérieure pour celle-ci, car il n'est pas seulement intéressant de connaître la complexité d'un problème, il est souhaitable de développer des algorithmes polynômiaux pour le résoudre de manière approchée. Nous avons proposé un nouvel algorithme d'ordonnancement basé sur la relaxation des contraintes d'intégrité d'un programme linéaire en nombre entiers modélisant le problème ![]() [4]. Nous avons prouvé que la performance relative de cet algorithme est de
[4]. Nous avons prouvé que la performance relative de cet algorithme est de ![]() et que cette borne est atteinte par une certaine classe de graphes. On peut noter que l'heuristique simple qui consiste à exécuter les tâches sur des processeurs différents en respectant les délais de communications admet une performance relative de 2. Nous avons également produit un algorithme
et que cette borne est atteinte par une certaine classe de graphes. On peut noter que l'heuristique simple qui consiste à exécuter les tâches sur des processeurs différents en respectant les délais de communications admet une performance relative de 2. Nous avons également produit un algorithme
![]() -approché pour une extension du problème étudié précédemment où les modules disposent de
-approché pour une extension du problème étudié précédemment où les modules disposent de ![]() processeurs identiques [4].
processeurs identiques [4].
De plus, nous avons étendu ce résultat au cas des petits délais de communications (voir [8]) en développant une heuristique avec une garantie de performance relative de
![]() , où
, où ![]() est le ratio entre le plus grand délai de communication et la plus petite durée d'une tâche du graphe de précédence i.e.
est le ratio entre le plus grand délai de communication et la plus petite durée d'une tâche du graphe de précédence i.e.
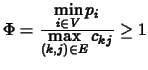 . Bien que le schéma général soit très proche de celui utilisé dans le cas précédent, nous avons été obligés d'utiliser des techniques sensiblement plus compliquées que celles utilisées précédemment aussi bien au niveau de la conception de l'algorithme que de l'analyse de sa performance dans le pire des cas.
. Bien que le schéma général soit très proche de celui utilisé dans le cas précédent, nous avons été obligés d'utiliser des techniques sensiblement plus compliquées que celles utilisées précédemment aussi bien au niveau de la conception de l'algorithme que de l'analyse de sa performance dans le pire des cas.
Nous nous sommes également intéressé à l'étude de l'impact de l'introduction de la duplication sur les problèmes d'ordonnancement avec communications hiérarchiques [1],[3]. Dans le cas du problème ![]() avec duplication, nous proposons un algorithme en deux étapes qui construit efficacement un ordonnancement de longueur minimale. La première étape de l'algorithme calcule pour chaque tâche la date d'exécution au plus tôt de ses copies construisant ainsi le graphe critique associé tandis que la seconde étape utilise le graphe critique et la possibilité de dupliquer les tâches pour construire l'ordonnancement optimal. La complexité de l'algorithme est en
avec duplication, nous proposons un algorithme en deux étapes qui construit efficacement un ordonnancement de longueur minimale. La première étape de l'algorithme calcule pour chaque tâche la date d'exécution au plus tôt de ses copies construisant ainsi le graphe critique associé tandis que la seconde étape utilise le graphe critique et la possibilité de dupliquer les tâches pour construire l'ordonnancement optimal. La complexité de l'algorithme est en ![]() .
.
Jusqu'à maintenant nos travaux se sont focalisés sur des problèmes d'ordonnancement avec une infinité de modules de processeurs. Par la suite, nos recherches se sont orientées vers des résultats tenant compte du fait que l'on dispose d'un nombre borné de modules de processeurs, c'est-à-dire nous considérons le problème ![]() avec un nombre fini de modules. Dans un premier temps nos recherches nous ont amené à développer plusieurs heuristiques, qui se basent sur la technique du pliage, dont la meilleure admet une performance relative de
avec un nombre fini de modules. Dans un premier temps nos recherches nous ont amené à développer plusieurs heuristiques, qui se basent sur la technique du pliage, dont la meilleure admet une performance relative de
![]() où
où
![]() désigne la performance relative sur une infinité de modules. Pour obtenir ce résultat, nous nous sommes basés sur la solution donnée sur une infinité de modules, et nous avons utilisé les techniques du pliage, des plus simples au plus élaborées pour garantir une solution réalisable. Il est important de noter qu'un pliage basé sur une décomposition par niveau du graphe de précédence conduit à un algorithme
désigne la performance relative sur une infinité de modules. Pour obtenir ce résultat, nous nous sommes basés sur la solution donnée sur une infinité de modules, et nous avons utilisé les techniques du pliage, des plus simples au plus élaborées pour garantir une solution réalisable. Il est important de noter qu'un pliage basé sur une décomposition par niveau du graphe de précédence conduit à un algorithme
![]() -approché avec
-approché avec ![]() le nombre de modules et
le nombre de modules et ![]() le nombre de processeurs par module. De plus, nous nous sommes intéressés à déterminer le seuil d'approximation pour un graphe biparti (graphe de profondeur deux), avec deux modules et un nombre arbitraire de processeurs identiques par module. Nous avons établi que le problème de décision associé est
le nombre de processeurs par module. De plus, nous nous sommes intéressés à déterminer le seuil d'approximation pour un graphe biparti (graphe de profondeur deux), avec deux modules et un nombre arbitraire de processeurs identiques par module. Nous avons établi que le problème de décision associé est
![]() -complet pour
-complet pour ![]() (avec ou sans duplication). Nous pouvons en déduire qu'il n'existe pas d'algorithme polynomial avec une garantie de performance relative inférieure à
(avec ou sans duplication). Nous pouvons en déduire qu'il n'existe pas d'algorithme polynomial avec une garantie de performance relative inférieure à ![]() .
.
En guise de conclusion, nous pouvons noter qu'un grand nombre de résultats se généralisent dans le cas du modèle à communications hiérarchiques. Il semble que le fait d'introduire un niveau de communication ne rend pas beaucoup plus difficiles les problèmes d'ordonnancement par rapport au modèle homogène. Cette conclusion n'est valide que sur les résultats que nous avons proposés. Il est évident qu'une étude reste à mener pour des problèmes où les hypothèses sont moins fortes pour valider cette constatation sur des problèmes plus généraux.