FAQ... on the paper "Deep learning is a good steganalysis tool when embedding key is reused for different images, even if there is a cover source-mismatch,"Lionel Pibre, Jérôme Pasquet, Dino Ienco, and Marc Chaumont, "Deep learning is a good steganalysis tool when embedding key is reused for different images, even if there is a cover sourcemismatch," in Proceedings of Media Watermarking, Security, and Forensics, Part of IS&T International Symposium on Electronic Imaging, EI'2016, San Francisco, California, USA, 14-18 Feb. 2016, 11 pages. (pdf).
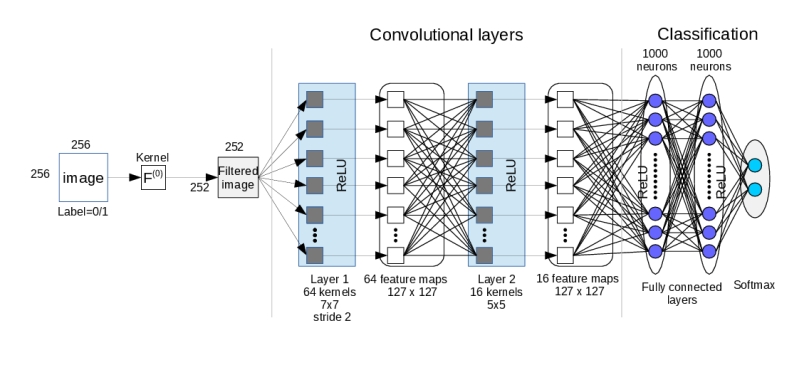
This page give additional information about the paper and the technical part related to the CNN and FNN that we proposed. Some parameters used with the Cuda-Convnet2 library (link):- Parameters of our CNN : layer-params-CNN.cfg, layers-CNN.cfg,- Parameters of our FNN ; layer-params-FNN.cfg, layers-FNN.cfg, - The python script that gets images as the input and applies the filter to them and stores them as batch files (there is a minor error with that script because the stored images are of size 256x256 and it should be 252x252; For the paper, this minor error has been corrected and the images size is 252x252; additionally the normalisation should to be done), here: make_batches.py. - The python meta file for the network input: meta.py. - The python script in which we define the specific DataProvider class: convdata.py. - A batch file made of 2 000 filtered images 256x256 (there is a minor error with that batch because images size should be 252x252 ; For the paper, this minor error has been corrected and the images size is 252x252) from the cropped BOSSBase database; 1000 covers, and 1000 S-UNIWARD 0.4 bpp stego ; embedding has been done with same key and the simulator (in double format - 64 bits ; stored through the use of Pickle module from Python ; this module allows object serialization; see https://docs.python.org/2/library/pickle.html) of training datas: data_batch_1. The databases:- The cropped BOSSBase database : CroppedBossBase-1.0-256x256_cover.rar.- The cropped BOSSBase stego images with S-UNIWARD at 0.4 bpp : CroppedBossBase-1.0-256x256_stego_SUniward0.4bpp.rar. - The LIRMMBase: link. FAQ :Q. Are you still using cuda-convnet2?A. Since september 2015, we use the "Digits" library. Q. Are cover and stego images paired up together even in each batch? A. During the training, covers and stegos are paired up together in each batch. With the testing set we also paired up covers and stegos. Q. Could you give more details on the FNN? A. We are only applying the High Pass Filter (F^(0)) and nothing more. Values are stored as double. Values are negative and positive, and those values are given to the FNN. There is not any normalisation in the FNN. Q. What is the input format for the CNN? A. In cuda-convnet2 we used a script in order to store the images in a kind of text file (named "batch" file) where pixel values can be stored as "double". This file is then given to the network. The script that we used applies the 5x5 high pass filter given in the paper, and then saves the (filtered) pixels values in the "batch" file. Q. When you prepared the database of 256x256 images from BOSSbase, did you embed them after cropping (embedding into 256x256 images) or did you embed the payload into the full size 512x512 and then cropped them into four? A. We have embeded in the 256x256 images from the cropped BOSSBase. Q. Which version of S-UNIWARD did you use in your experiments? A. For S-Uniward, the C++ linux version has been used. The same key has been used for embedding and embedding has been done with the simulator. Q. What was the value of the stabilizing constant that is used in S-UNIWARD to prevent dividing by zero in computing the embedding costs? A. The sigma is equal to 1 as recommanded in the fixed version. Q. What are the CNN and FNN parameters. A. Parameters are given in the parameters files (see above). Q. Do you change the learning rate adaptively after several epochs? A. No. Q. Do you shuffle the images in the database after each epoch? A. No. Q. Is this correct or is it a typo and the experiments were done on BOSSbase 1.01? A. The experiments were done on BOSSbase 1.0 and not BOSSbase 1.01. Q. Why my CNN does not give good results? A. Are you in the right scenario ("same key + simulator")? Otherwise, your network is too big, you do not wait enough time (the network has not converged), the learning rate is not well tuned (with cuda-convnet2 it is 0.001, and with Caffe, it is is better to select a value of 0.0001)... |



