
Le module image vous est proposé par le projet ICAR (image et interaction)





| .......
Module Image .......
Le module image vous est proposé par le projet ICAR (image et interaction) |
|
|
|
 Olivier
Strauss, LIRMM,
département robotique. 04 67 41 85 87. Marc Chaumont,
LIRMM,
département informatique.
04 67 41 85 14.
Olivier
Strauss, LIRMM,
département robotique. 04 67 41 85 87. Marc Chaumont,
LIRMM,
département informatique.
04 67 41 85 14.
|
sur le module image en
envoyant un e-mel (cliquez sur le penseur). |



 : Pour vous connecter sur la
page institutionnelle de l'intervenant
: Pour vous connecter sur la
page institutionnelle de l'intervenant  : Pour
récupérer une
présentation (lorqu'elle nous a été transmise)
: Pour
récupérer une
présentation (lorqu'elle nous a été transmise)  Mercredi 26
avril - 9h00-12h00 : Télédétection : utilisation de l'imagerie
hyperspectrale pour l'étude de la végétation arborée.
Karine Adeline
: DOTA/POS – ONERA
– Toulouse.
Mercredi 26
avril - 9h00-12h00 : Télédétection : utilisation de l'imagerie
hyperspectrale pour l'étude de la végétation arborée.
Karine Adeline
: DOTA/POS – ONERA
– Toulouse.| La
télédétection est une technique d’acquisition d’images permettant de
remonter à la caractérisation de surfaces terrestres à distance. Nous
nous intéresserons particulièrement à l’imagerie optique passive dont
le principe repose sur la mesure du rayonnement électromagnétique
solaire ayant interagi avec l’atmosphère et les éléments présents au
sol. Chaque élément, qu’il soit de nature artificielle ou naturelle,
possède différentes propriétés optiques qui peuvent être observables à
différentes échelles spatiales à partir d’un capteur aéroporté et
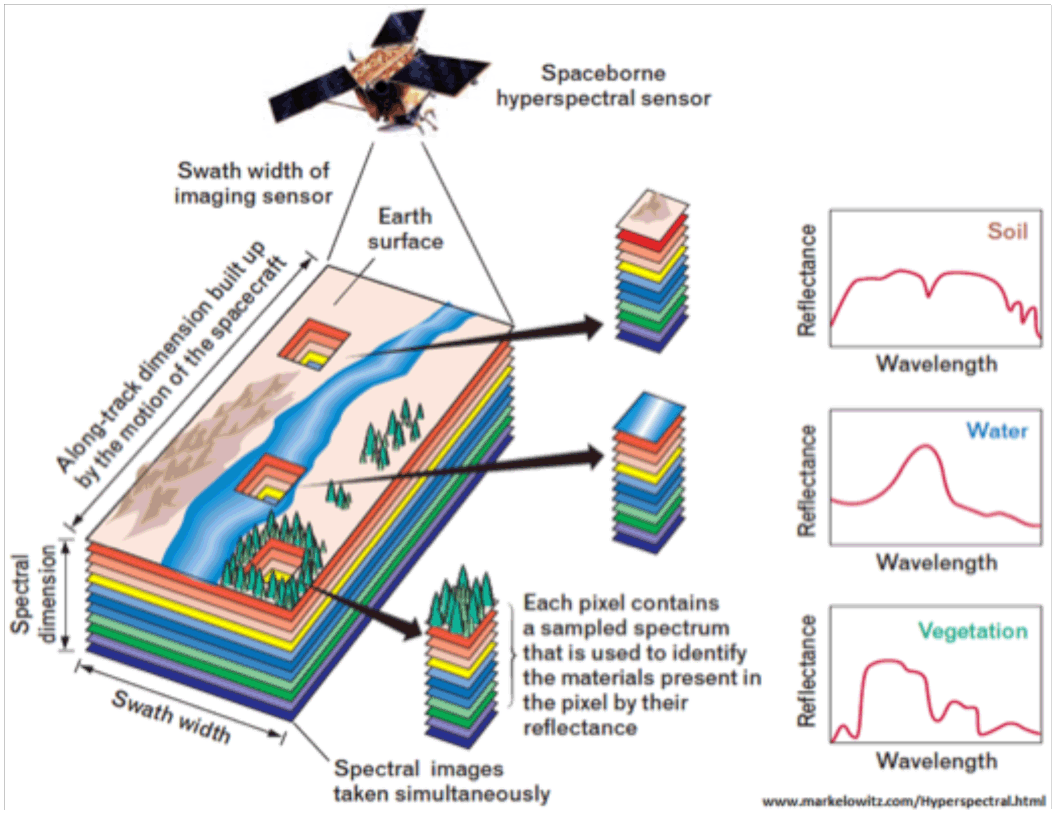
satellitaire. Une image hyperspectrale est représentée par une
information tridimensionnelle : une surface 2D de pixels imagée par le
capteur et un signal 1D acquis sur plusieurs longueurs d’onde
déterminant la réponse spectrale des éléments présents dans chaque
pixel. |
 |
 |
Ce cours examinera les principes physiques de la télédétection et du transfert radiatif Terre-atmosphère afin d’appréhender les challenges rencontrés avant d’obtenir l’information finale cartographiée. Enfin, un exemple applicatif permettra d’illustrer l’utilisation de l’imagerie aéroportée hyperspectrale pour caractériser le suivi multi-temporel de la santé des arbres face à l’impact d’un épisode de sécheresse. |
Mercredi 26
avril - 14h00-17h00
: La vision par ordinateur : de la 2D à la 3D.
Cédric Demonceaux :
Le2I - Université de Bourgogne – Le Creusot.| La
vision par ordinateur consiste à analyser une scène à partir d’images.
C’est un domaine relativement vaste allant du traitement du signal à
l’intelligence artificielle. Bien que cette discipline soit
relativement jeune, elle a fait l’objet de nombreuses recherches tant
sur le plan académique, technologique qu’industriel. |
 |
 |
Dans cet exposé, nous verrons dans un premier temps comment cette discipline a progressé au cours du temps en évoquant les méthodes fondatrices d’analyse d’images 2D. Puis nous montrerons comment à partir d’images de la scène il est possible de reconstruire en 3D l’environnement. Nous distinguerons trois moyens pour y parvenir : les systèmes multi-caméras, la géométrie multi-vues pour les systèmes mono-caméra en déplacement et les caméras 3D. |
| Par la suite, nous en déduirons à travers des exemples concrets que ces techniques sont désormais bien maîtrisées. Dans une seconde partie, nous verrons que si nous disposons d’informations a priori sur la scène qu’il est encore possible d’améliorer les résultats de la littérature. Pour ce faire, nous présenterons les résultats originaux et récents de notre équipe sur la reconstruction 3D à partir d’a priori. |  |
Jeudi 27
avril - 9h00-12h00 : Les mystères du Deep Learning.
Valentin Leveau : IRIT - Université Paul Sabatier - Toulouse. | Depuis
les années 50, nous rêvons de pouvoir mettre en place des systèmes dits
“intelligents” dont l’une des caractéristiques serait de pouvoir
apprendre à partir d’exemples à effectuer certaines tâches tout en
étant capable de s’adapter à des exemples qui n’ont pas été vu pendant
cette phase d’apprentissage. Pour ce faire, il est nécessaire de
comprendre les liens, la structure sous-jacente, qu’il peut y avoir
dans les données d’entrée afin de pouvoir prédire certaines variables
(ou grandeures) à partir de l’observation d’autres variables (e.g.
prédire l’objet contenu dans une image à partir des ses pixels). Ces
mécanismes d’apprentissage sont l’objet d’étude du Machine Learning (ou
apprentissage automatique) qui est un cas général du Deep Learning
(apprentissage profond). Dans le cas de la reconnaissance d’images, les
algorithmes “classiques” de Machine Learning consistent souvent à 1)
représenter dans un premier temps l’image par une abstraction (souvent
sous la forme d’un vecteur) contenant l’information “utile” permettant
décrire son contenu visuel puis 2) d'apprendre les relations entres les
éléments de cette abstraction pour prédire la classe de l’objet
représenté. | 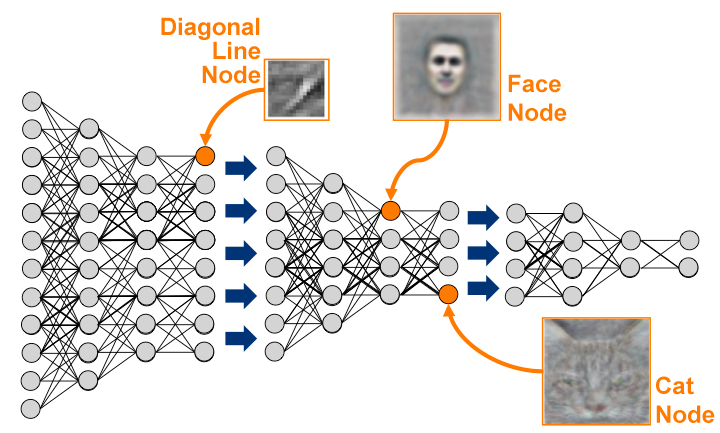 |
 |
Le
paris du Deep Learning consiste à 1) ne plus considérer séparément la
phase d’abstraction/représentation d’image et l'algorithme
d’apprentissage mais également 2) à produire plusieurs niveaux
d’abstraction pour encoder des concepts de plus en plus hauts niveaux
faisant progressivement la transition de l’espace des pixels vers
l’espace des labels. Dans la première partie de cet exposé, nous essaierons de comprendre quelles sont les propriétés que les représentations intermédiaires des images devraient avoir pour permettre de bonnes performances de reconnaissance. Nous verrons comment et pourquoi les approches profondes sont de très bonnes candidates pour se rapprocher de ces objectifs. Nous aborderons ensuite les bases des procédures d’apprentissage supervisées des réseaux de neurones profonds, notamment les architectures convolutives pour la reconnaissance d’images. Bien qu’elles existent depuis les 80, les techniques de Deep Learning ne sont devenues que très récemment massivement connues et reconnues dans le monde académique et sont désormais au coeur de nombreux services proposés dans l’industrie. Nous verrons donc quels progrès, ont permis à ces architectures de devenir état de l’art sur de nombreux problèmes de visions. |
| Nous verrons dans la deuxième partie que les approches supervisées disposent de certaines limitations dans le sens où ne garder que les informations discriminantes des classes peut s’averer sous optimal en terme de capacité de généralisation. Effectivement, si l’on s’inspire de la manière dont nous fonctionnons, il est clair que nous passons la plus part notre temps à comprendre le sens commun des choses en observant simplement les régularités du monde qui nous entoure sans constamment avoir accès aux labels des objets que nous voyons. Nous aborderons donc les principes de l’apprentissage (profond) non-supervisé où les exemples d’apprentissage sont fournis sans labels permettant ainsi d’encoder un contenu d’information plus riche. Nous verrons enfin que, bien que les approches profondes semblent régler biens des problèmes de vision avec des performances satisfaisantes, ces dernières soulèvent encore de nombreux problèmes qu’il conviendrait de résoudre pour se rapprocher d’avantage de systèmes ayant des capacités de généralisation se rapprochant de celles des humains. Nous aborderons certaines de ces limites et verrons en quoi elles constituent aujourd’hui de réel verrous scientifiques et donc des sujets de recherche très actifs. |  |
Jeudi 27
avril - 14h00-17h00
: Comment réconcilier astronomie et classification?
Johanna Pasquet et Jérôme Pasquet
: LSIS - Marseille. | Les
sciences de l'Univers sont fondamentales pour comprendre le monde dans
lequel nous vivons ainsi que son évolution. Observer des objets
lumineux tels que des galaxies ou des étoiles est un moyen d'avoir
accès à différentes propriétés de notre Univers. Néanmoins, il est
important d'avoir une certaine statistique afin d'en déduire des
paramètres cosmologiques. Avec les avancées sur la mécanique et le
stockage et le traitement des données, de grands relevés du ciel sont
possible avec une cadence très élevée. De cette façon, il est essentiel
de se tourner vers des méthodes d’apprentissage automatique pour la
classification et la détection des objets observés. Les méthodes de
machine learning ont alors fait leur apparition et montrent de bons
résultats. |

|
 |
Au cours de ce cours, nous reprendrons dans un premier temps les bases de l’astronomie, en passant en revue différents objets astronomiques qui ont un intérêt majeur pour la compréhension de notre Univers. Puis nous montrerons la nature des différents signaux en astronomie, ainsi que les différentes méthodes de machine learning appliquées. Enfin nous exposerons nos derniers résultats concernant le Deep learning appliqué à des noyaux actifs de galaxie, les quasars. |
Vendredi 28
avril - 9h00-12h00 : De la compression à la théorie algorithmique de
l'information.
Francois Cayre
: GIPSA-lab - Grenoble.| Si
on ne compte plus les succès de la théorie de l'information
probabiliste classique due à Claude Shannon, elle s'inscrit en réalité
dans une conception plus large de la notion d'information, que la
théorie développée, entre autres, par Andréï Kolmogorov permet de
compléter, et, dans une certaine mesure, d'étendre. |  |
| Dans une première partie, ce cours présentera en détails le fonctionnement d'une méthode classique de compression sans perte (DEFLATE, utilisée dans gzip, WinZip, etc.) pour illustrer la complémentarité des approches probabiliste (Huffman) et algorithmique (Lempel-Ziv). | |
 |
|
| La
seconde partie s'attachera à développer une théorie de l'information
fondée exclusivement sur l'algorithme de Lempel-Ziv (1977) et ses
variantes (classification universelle de Ziv-Merhav), sans aucune
considération probabiliste et malgré tout intuitive. Nous montrerons
comment calculer des estimateurs pour les complexités simple,
conditionnelle et jointe, ainsi qu'une semi-distance universelle et des
estimateurs de causalité sur graphes directs acycliques. Les applications iront de la classification (ADN, langues) à la reconstruction de l'historique de la rédaction d'une oeuvre littéraire. On ouvrira sur le traitement de signaux cérébraux. |
 |
Vendredi
28
avril - 14h00-15h30
: Danse et numérique : une conjugaison au service de l’exploration,
démonstrations, décryptages et interactivité avec les spectateurs.
Ysis Percq
: Journaliste – France.| Apprivoiser,
dompter, ou, au contraire, le considérer comme un facilitateur de
créativité : le numérique est un champ des possibles dont seul
l’artiste en définit les limites. Depuis l’incursion de la vidéo sur
scène, à l’intégration de robots, jusqu’aux drones aux côtés des
danseurs, les nouvelles technologies évoluent et font évoluer les
cultures chorégraphique et scénographique. Vision futuriste, plongeon dans le vortex, les artistes en quête d’expériences prennent à bras-le-corps cette mutation, tant pour nourrir leurs réflexions chorégraphiques que pour leur venir en aide sur des questions de répertoire et d’écriture.  Kiss & Cry de Michèle Anne De Mey et Jaco Van Dormael | PIXEL de Mourad Merzouki © Laurent Philippe Avec l’avènement des start-up, la danse n’échappe pas aux algorithmes, au service de la créativité. Une machine et un interprète ? Un chorégraphe informaticien ? Un codeur-danseur ? la transversalité digitale promet un avenir fertile, imaginatif, surprenant. nous n’en sommes qu’à l’aube… |
| Vous pouvez récupérer les différentes séquences de la présentation d'Ysis Percq sur les liens ci-dessous : Hands Drawn Spaces, Merce Cunningham Decouflé La Magie Nouvelle Adrien M et Claire B Blanca Li Danse avec les drones par BUYMA Inferno Compagnie Gilles Jobin (danse avec la réalité virtuelle + 3D) Mr & Mme Rêve Compagnie KDanse Projet européen (attention il y a deux liens) Sarah Alaoui |
Vendredi
28
avril - 16h00-17h00
: Les robots humanoïdes nous semblent-ils si amicaux ? Adrien Gomez
: Professeur en multimedia - LIRMM – France.| L’acceptation
des robots est un sujet largement abordé dans la communauté
scientifique, en particulier dans les études transversales de
psychologie et de robotique. Ces études se focalisent essentiellement
sur l’aspect comportemental des êtres humains vis-à-vis des robots. De nombreuses études prennent pour base la théorie de l’uncanny valley du roboticien Mori Masahiroii. Cette théorie démontre que si un robot androïde s’approche de l’apparence réaliste d’un être humain, il sera sujet à un rejet de la part de ces derniers. Cela vient du fait que nous percevons dans le comportement et l’apparence des autres individus des choses qui sont (encore à l’heure actuelle) impossible à reproduire au niveau mécanique (on peut probablement appliquer cette théorie aux personnages en images de synthèse, film d’animation, de performance capture ou de jeux vidéo). En partant de ce postulat, il a été possible de déterminer différentes pistes de recherche que l’on peut vraisemblablement appliquer aux robots zoomorphiques. (Peut-on appliquer le principe de l’uncanny valley aux robots zoomorphes ?) |  |