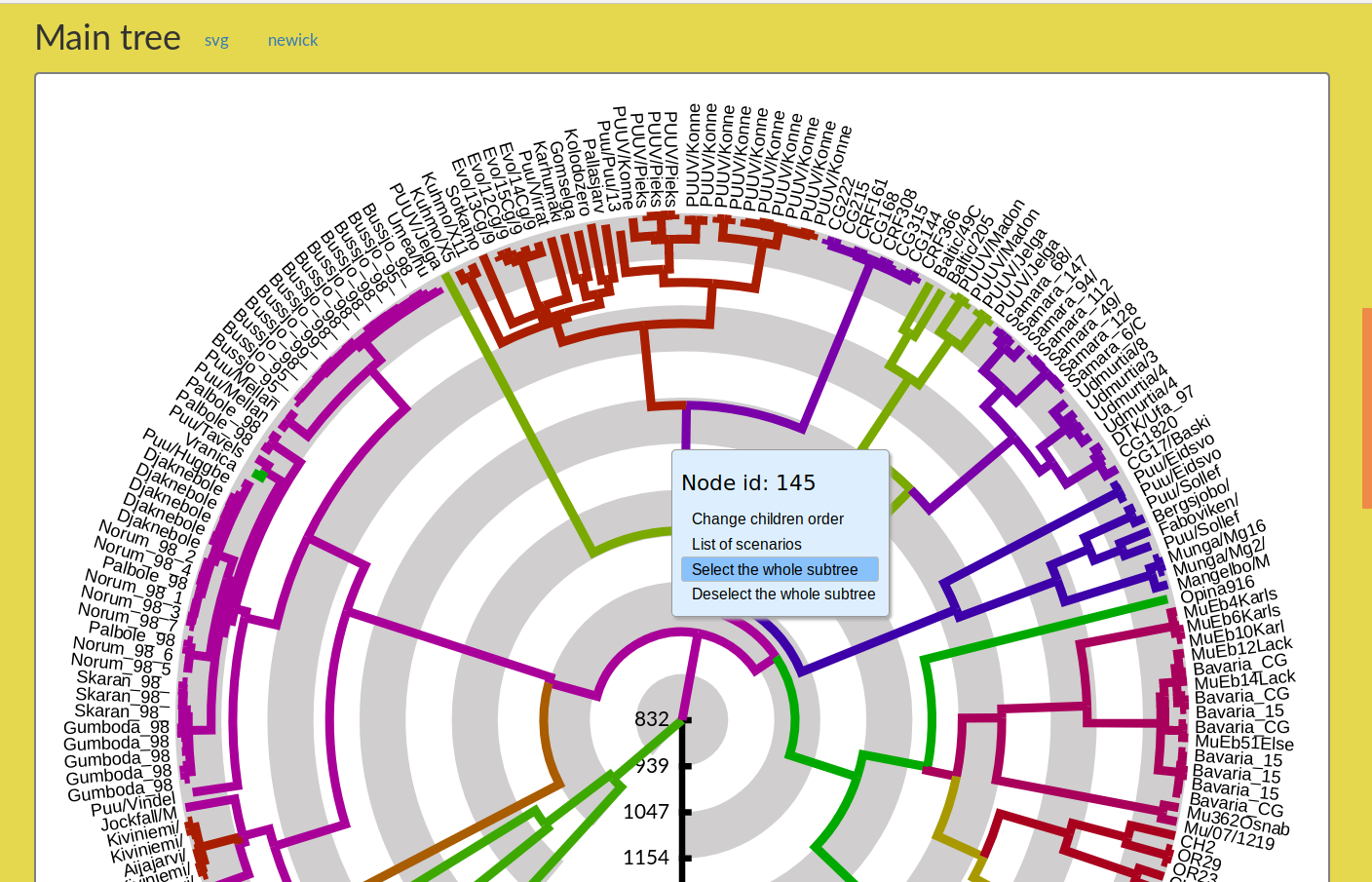
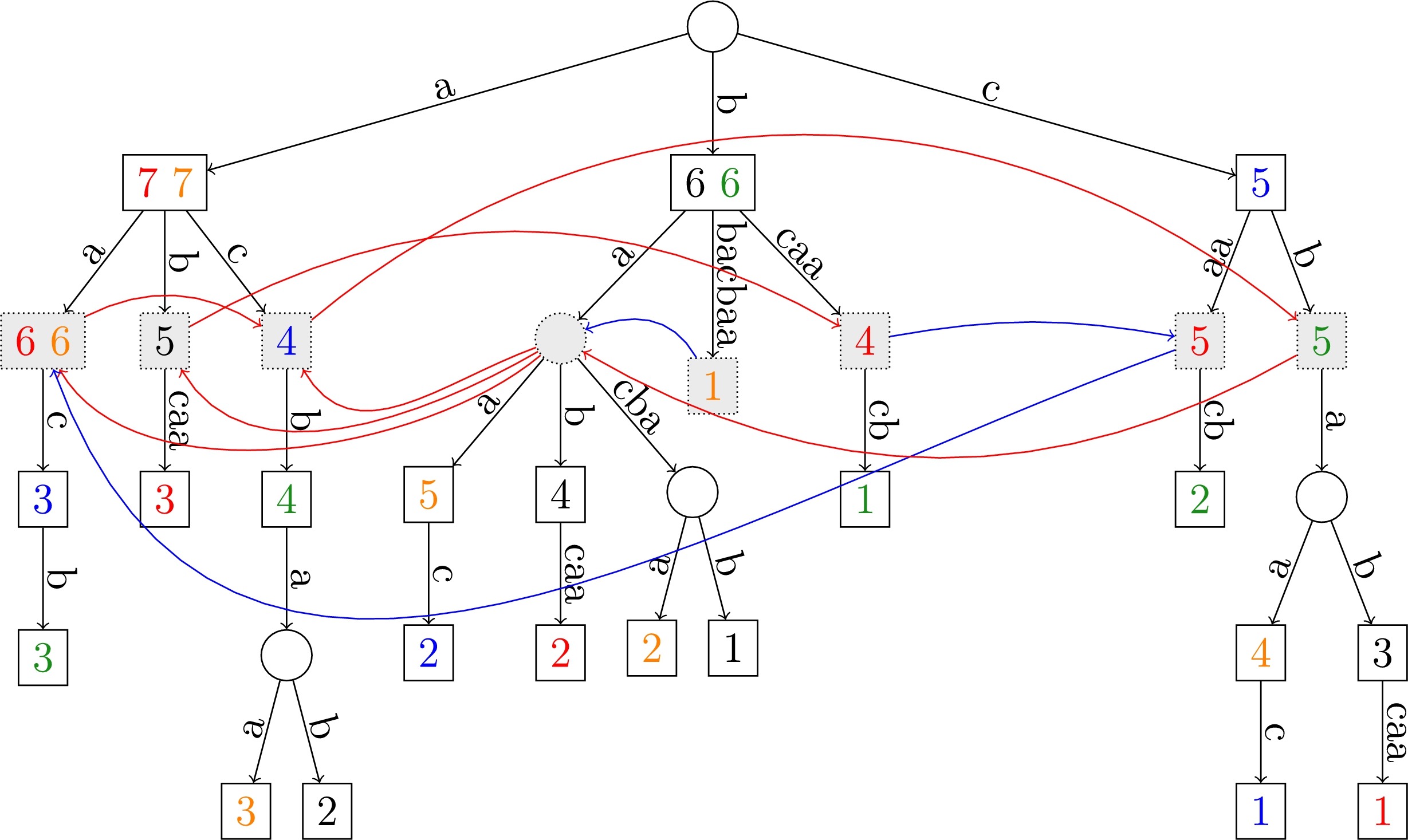
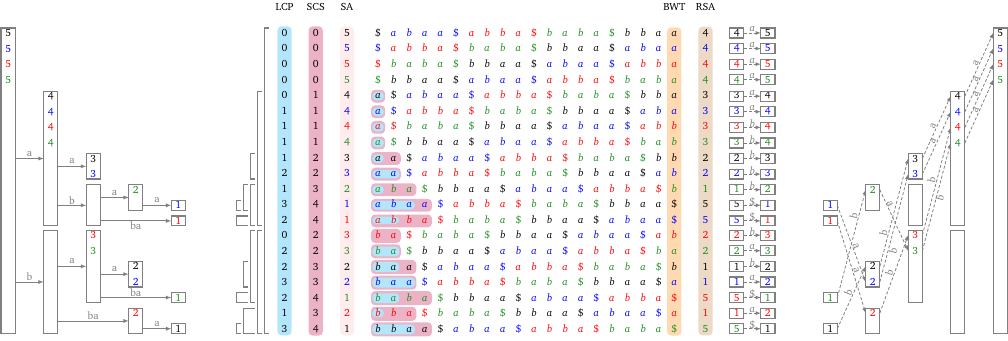
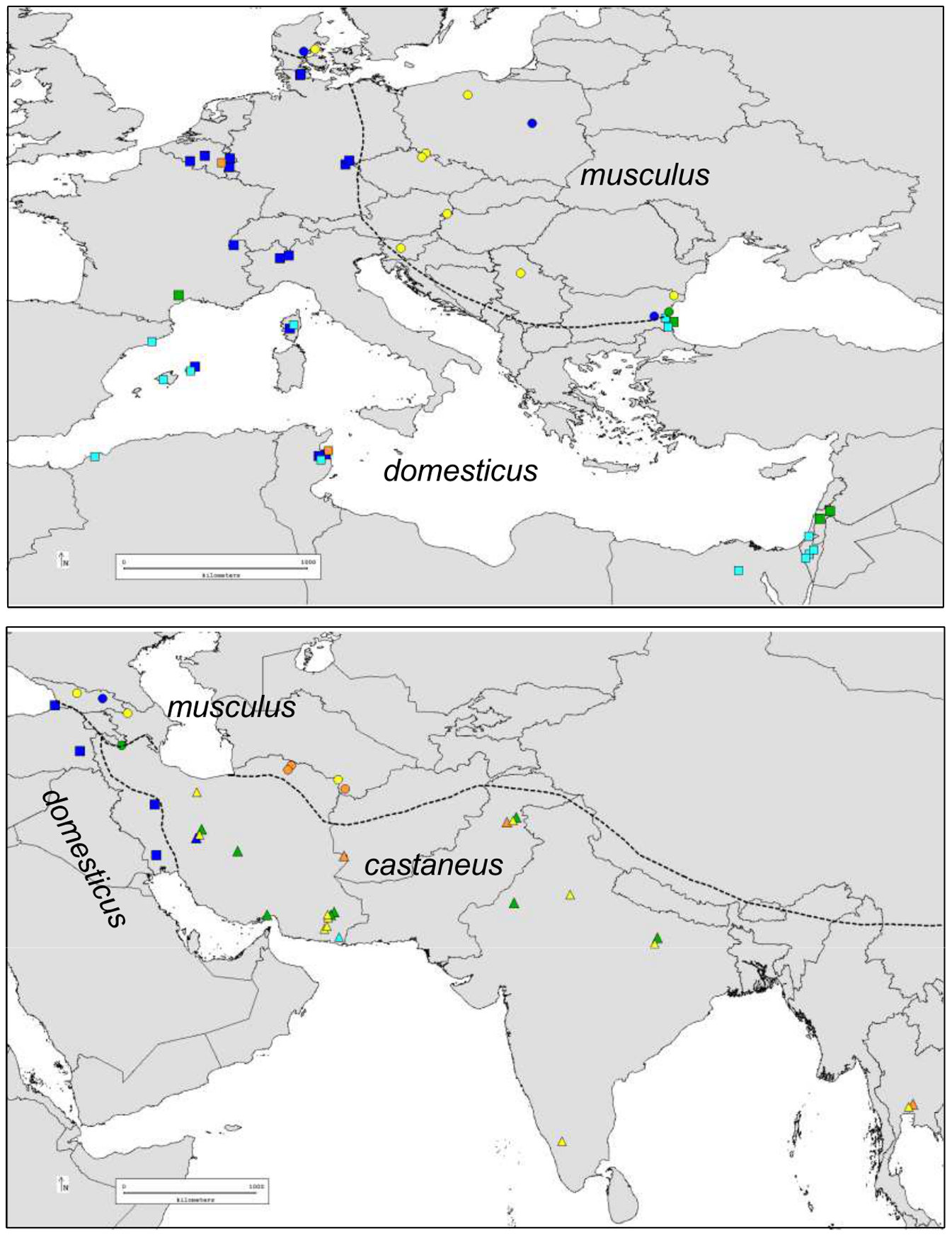
Eric Rivals
CNRS Research Director in Computer Science and Bioinformatics,
Centre National de la Recherche Scientifique
University Montpellier
Multi-disciplinary researcher at the nexus of computer science, bioinformatics and biology.
Co-head of bioinformatics platform ATGC.
Principal investigator of several pluri-disciplanary projects.
View ResumeEducation
-
Habilitation, 2005
Montpellier University
-
PhD in Computer Science, 1996
Lille I University
-
Master in Computer Science, 1993
Lille I University
-
Master in Programming, Artificial Intelligence, 1991
Lille I University
Interests
- String algorithms
- Data indexing
- Sequence analysis
- Data structures
- Genomics
- Data mining, AI
- Information Retrieval
- Cancer